分类问题Classification
逻辑回归(Logistic Regression)是一种用于解决分类问题的统计学习方法,尽管名字中带有“回归”,但它实际上是一种分类算法。逻辑回归主要用于二分类问题,即将数据分为两个类别,但它也可以通过一些变种扩展到多分类问题。
逻辑回归的基本思想是通过一个线性函数的加权和,将输入特征映射到一个介于0和1之间的概率值,表示属于某一类别的概率。为了将线性函数的输出转化为概率,逻辑回归使用了一个称为“逻辑函数”或“Sigmoid函数”的非线性转换。逻辑回归在实际应用中被广泛使用,尤其适用于二分类问题,例如信用风险评估、医疗诊断、广告点击预测等。
以下还是以二元分类为例子:
将因变量(dependent variable)可能属于的两个类分别称为负向类(negative class)和正向类(positive class),则因变量y∈0,1 ,其中 0 表示负向类,1 表示正向类。
如果用线性回归算法来解决一个分类问题,对于分类, y取值为 0 或者1。但实际情况中,假设函数的结果可能大于1或小于0,所以采用逻辑回归算法来解决该问题。逻辑回归算法的性质是:它的输出值永远在0到 1 之间。
假设陈述
假设表示,特别是在机器学习和统计学的背景下,指的是数学或功能表达式,用于模拟给定问题中输入变量(特征)与输出变量(目标)之间的关系。假设代表着算法试图从数据中捕捉到的学习或假设的模式。
在线性回归的情况下,假设表示为将输入特征与输出变量相关联的线性函数。

在逻辑回归的背景下,假设表示涉及使用逻辑或 Sigmoid 函数来模拟二元输出的概率。

训练机器学习模型的目标是找到假设表示中的参数(θ 值)的最优值。通常通过梯度下降等优化技术实现,算法迭代地调整参数,以最小化训练数据中预测值与实际值之间的差异。
假设表示定义了机器学习模型中输入特征与预测输出之间的功能关系。这是训练模型和根据从数据中学到的模式进行预测的关键组成部分。
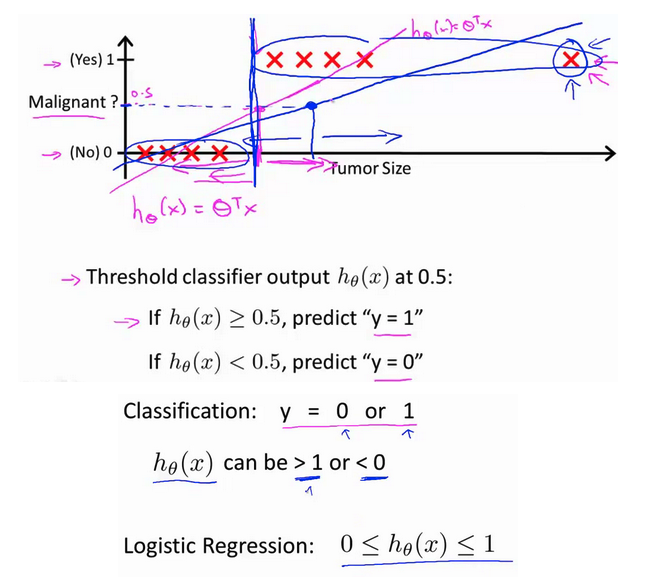
以乳腺癌分类问题,我们可以用线性回归的方法求出适合数据的一条直线:
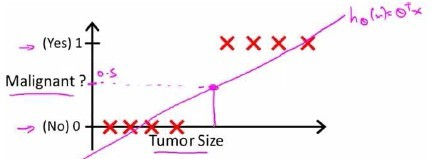
根据线性回归模型我们只能预测连续的值,然而对于分类问题,我们需要输出0或1,我们可以预测:

对于左图所示的数据,这样的一个线性模型似乎能很好地完成分类任务。假使我们又观测到一个非常大尺寸的恶性肿瘤,将其作为实例加入到我们的训练集中来,这将使得我们获得一条新的直线。
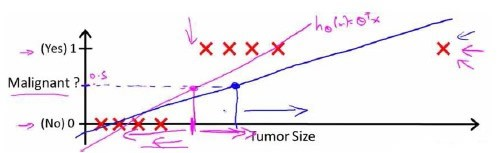
这时,再使用0.5作为阀值来预测肿瘤是良性还是恶性便不合适了。可以看出,线性回归模型,因为其预测的值可以超越[0,1]的范围,并不适合解决这样的问题。
引入一个新的模型,逻辑回归,该模型的输出变量范围始终在0和1之间。
逻辑回归模型的假设是:
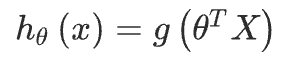
其中: 代表特征向量 代表逻辑函数(logistic function)是一个常用的逻辑函数为S形函数(Sigmoid function),公式为:
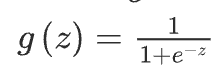
该函数的图像为:
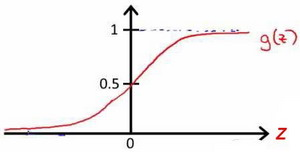
合起来,我们得到逻辑回归模型的假设:

判定边界Decision Boundary
判定边界(Decision Boundary)是在分类问题中的一个概念,它表示样本被分类为不同类别的分界线或曲面。在机器学习算法中,判定边界是根据训练数据和模型参数所确定的,它决定了模型如何将不同类别的样本分开。
对于二分类问题,判定边界是一个在特征空间中的曲线、平面或超平面,用于将不同类别的样本分隔开。这意味着在判定边界的一侧,样本被归类为一类,而在另一侧则被归类为另一类。判定边界的位置和形状取决于所使用的分类算法和特征表示。
例如,在逻辑回归中,判定边界是通过逻辑函数(Sigmoid函数)来定义的。对于一个简单的二维情况,判定边界可以是一条直线,它将特征空间分成两个区域,每个区域对应一种类别的样本。在支持向量机(Support Vector Machine,SVM)中,判定边界是将不同类别的样本分开的超平面,它尽可能地使各类别样本距离判定边界最大化。
在实际应用中,了解判定边界的位置和形状可以帮助我们理解模型的分类能力以及模型如何对不同类别的样本进行区分。优秀的判定边界能够在训练数据和未见数据上都具有良好的分类性能。
假设我们有一个模型:
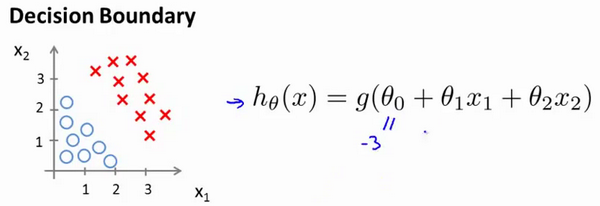
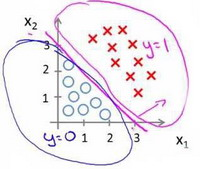

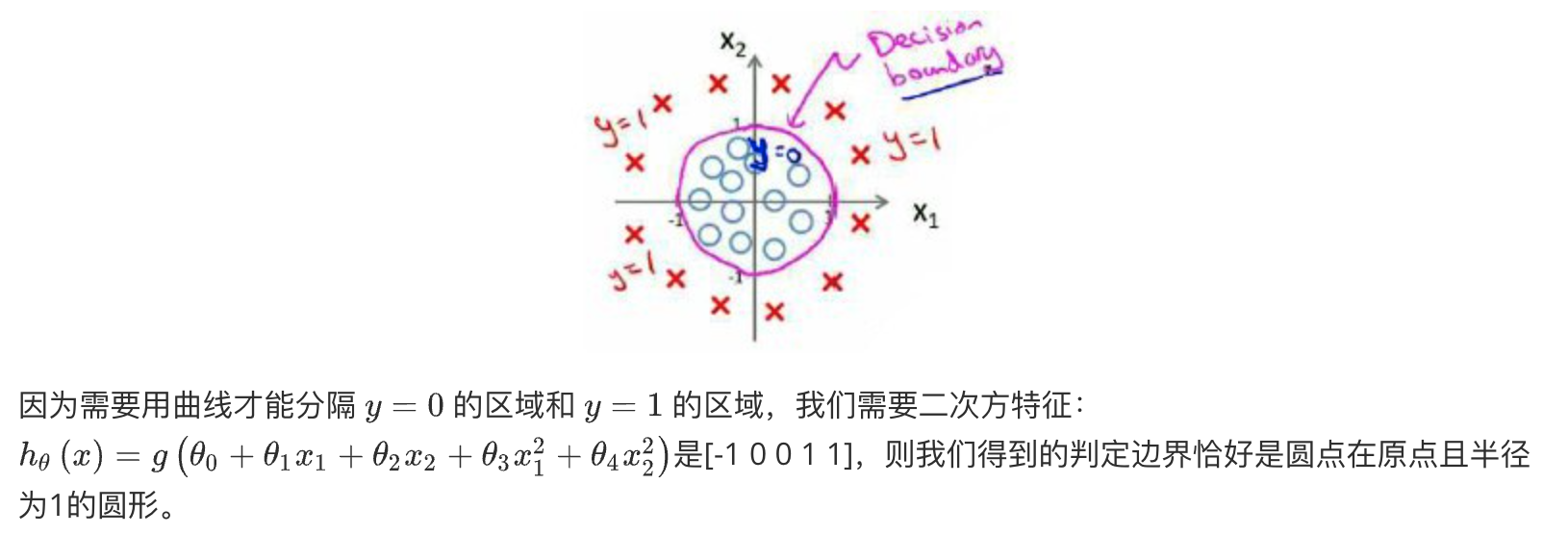
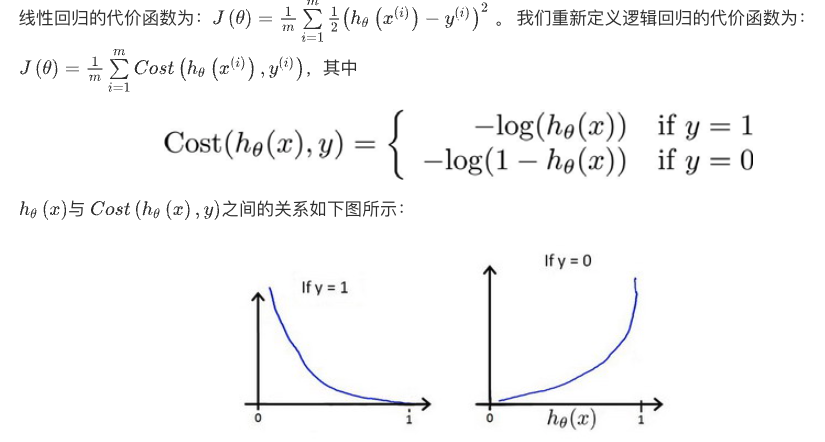
代价函数Cost Function
逻辑回归的代价函数(Cost Function)是用来衡量模型预测结果与实际标签之间的误差的函数。在逻辑回归中,代价函数用于衡量模型的预测概率与实际类别标签之间的差异,从而帮助优化算法调整模型参数,以使预测结果更接近实际情况。
逻辑回归的代价函数通常使用对数似然损失函数来定义。假设我们有训练样本 (x(i),y(i)),其中 x(i) 是输入特征,y(i) 是实际的二元类别标签(0 或 1)。

代价函数的目标是最小化预测误差,使得模型的预测概率接近实际类别标签。通常使用梯度下降等优化算法来寻找使代价函数最小化的模型参数 θ。

对于线性回归模型,定义的代价函数是所有模型误差的平方和。理论上来说,我们也可以对逻辑回归模型沿用这个定义,但是问题在于,当
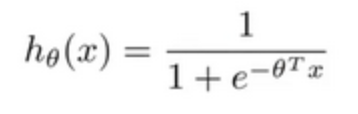
带入到这样定义了的代价函数中时,我们得到的代价函数将是一个非凸函数(non-convexfunction)。
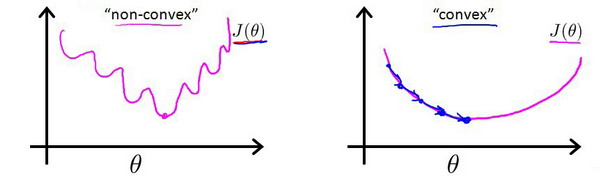
这意味着我们的代价函数有许多局部最小值,这将影响梯度下降算法寻找全局最小值。
一些梯度下降算法之外的选择: 除了梯度下降算法以外,还有一些常被用来令代价函数最小的算法,这些算法更加复杂和优越,而且通常不需要人工选择学习率,通常比梯度下降算法要更加快速。这些算法有:共轭梯度(Conjugate Gradient),局部优化法(Broyden fletcher goldfarb shann,BFGS)和有限内存局部优化法(LBFGS)。
简化的成本函数和梯度下降Simplified Cost Function and Gradient Descent


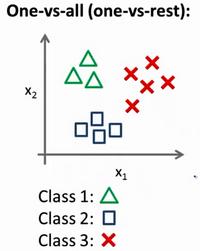
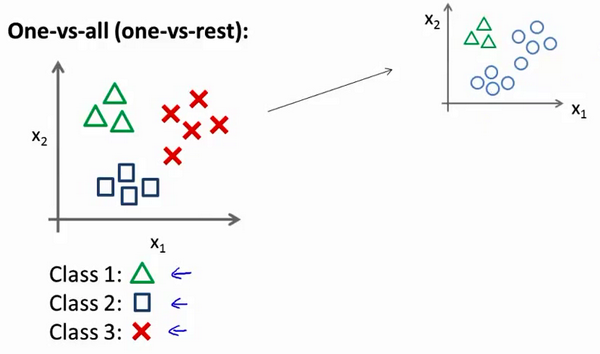
多类别分类:一对多Multiclass Classification_ One-vs-all
多类别分类,也称为多类别分类问题,是指在一个问题中有多个类别需要进行分类。一对多(One-vs-all,OvA)是一种常用的多类别分类方法,它将多类别分类问题分解为多个二分类问题来解决。
在一对多方法中,对于每个类别,都创建一个二分类模型,将这个类别视为“正类”而其他类别视为“负类”。这样,对于有 N 个类别的问题,就会产生 N 个二分类模型。当需要对一个新样本进行分类时,每个二分类模型都会给出一个预测分数,最终选择预测分数最高的类别作为最终分类结果。
一对多方法的优点在于它将多类别分类问题转化为了一组简单的二分类问题,适用于各种分类算法。然而,这种方法可能存在类别不平衡的问题,特别是在某些类别样本数量远多于其他类别时,可能会导致预测结果偏向数量较多的类别。
"一对余"方法