概论
定义
嵌入是翻译后的词语,更贴切的翻译建议是“向量化”;将对象向量化,完成数值化的转换。
Embedding 就是用一个数值向量“表示”一个对象(Object)的方法。“实体对象”可以是image、word等,“数值化表示”就是一个编码向量。例如对“颜色“这种实体对象用(R,G,B)这样一个三元素向量编码。
在推荐系统中,其核心就是Embedding。
为什么有Embeddings
假如我们需要对以下文本进行数值化,就需要确定编码:
| 字符 | p | m | s | o | l |
| 编码 | 1 | 2 | 3 | 4 | 5 |
那么,pmsolo的一维即 [1 2 3 4 5 4],将该编码转换成one hot encoding,就变成了
[
[1 0 0 0 0 ] //p
[0 1 0 0 0 ] //m
[0 0 1 0 0 ] //s
[0 0 0 1 0 ] //o
[0 0 0 0 1 ] //l
[0 0 0 1 0 ] //o
]经过这样的编码后,pmsolo就变成了一个二维的矩阵;由于其存在大量的为0的数字,所以一般称为稀疏矩阵。稀疏矩阵做矩阵计算的时候,只需要把1对应位置的数相乘求和即可,计算便捷快速。但其缺点是过于稀疏,会过渡占用资源。
于是Enmeddings出现了。
Enmeddings可用来升降维度
在上文中,pmsolo最终是一个6*5的矩阵,在大学线性代数课本中学过矩阵的乘法,将该6*5矩阵乘以一个5*2的矩阵,将会得到一个6*2的矩阵。
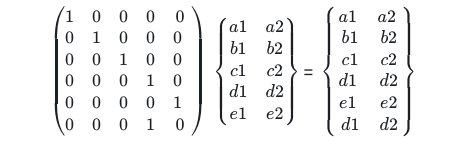
通过这种方法我们将一个稀疏的矩阵变成了一个较小的矩阵,中间的矩阵其实就是节点数为2的全连接神经网络层。Embeddings以one hot 为输入;中间层节点为词向量维度的全连接层,即词向量表。通过该方法降低了运算量,因为把one hot型的矩阵运算简化为了查表操作。
相反,也可以对某矩阵进行提升维度。对低维的数据进行升维时,可能把一些其他特征给放大了,或者把笼统的特征给分开了。
| 特点 | One-Hot 编码 | 嵌入(Embeddings) |
| 表示形式 | 稀疏的、二进制表示,大多数元素为0或1 | 密集的、连续向量表示,包含多个实数值 |
| 维度 | 取决于词汇表的大小,维度较高 | 维度通常较低,因为它捕捉语义关系 |
| 语义关系捕捉 | 不擅长捕捉词之间的语义关系 | 能够捕捉词之间的语义相似性 |
| 内存占用 | 占用较多的内存空间,随着词汇表增加而增加 | 占用较少的内存空间,因为维度通常较低 |
| 稀疏性 | 结果是稀疏的向量,只有一个元素为1 | 结果是密集的向量,多个实数值构成 |
| 计算效率 | 可能会因高维度而导致计算效率低下 | 由于维度较低,计算效率较高 |
| 上下文信息 | 不能很好地捕捉上下文信息,每个词都是独立编码 | 能够在向量空间中捕捉上下文信息,包括词之间的关联 |
| 适用领域 | 适用于某些简单的分类和回归任务 | 在NLP领域广泛用于语义表示、文本生成等任务 |
Enmeddings如何工作
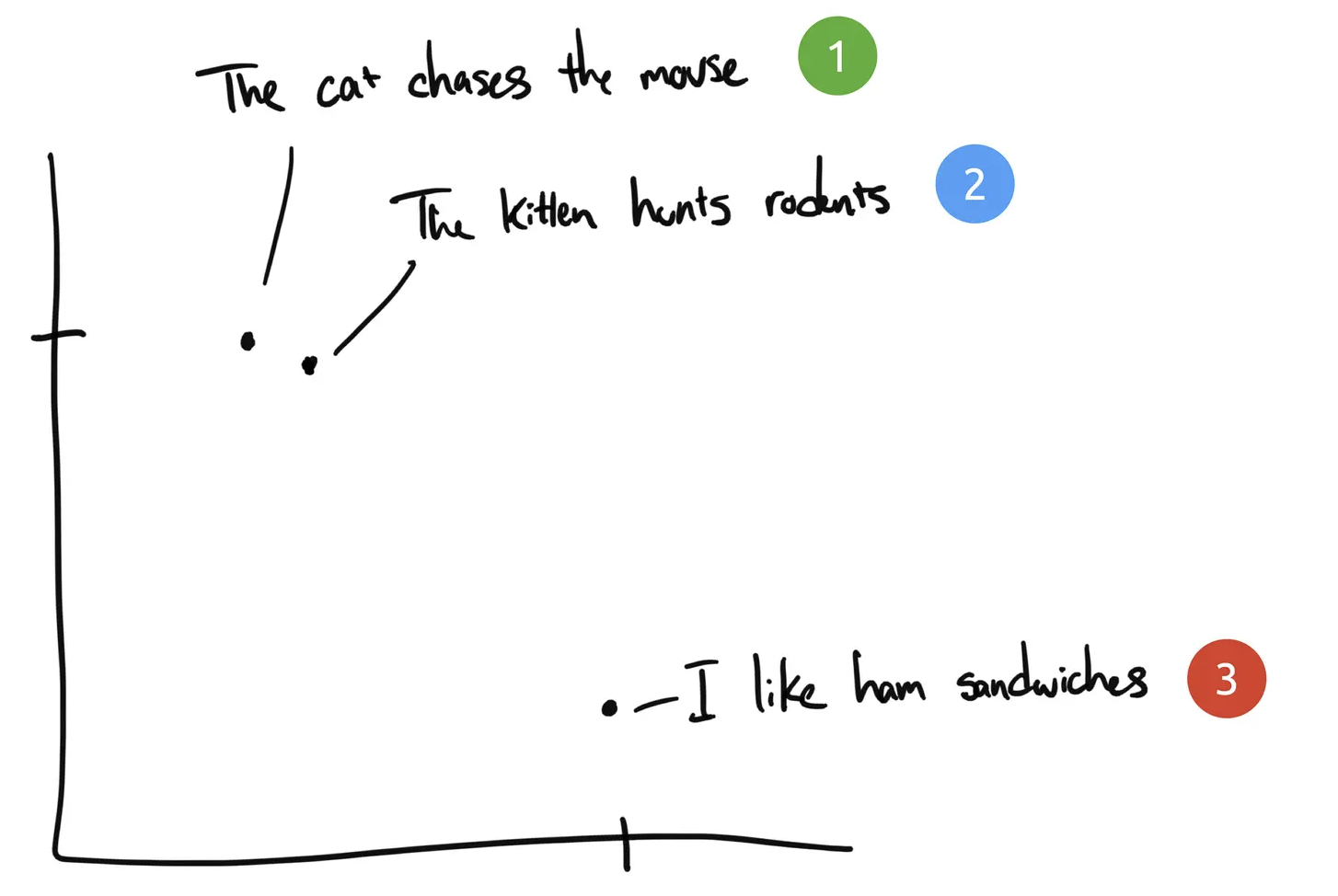
假设有三个短语:
- “The cat chases the mouse”(猫追逐老鼠)
- “The kitten hunts rodents”(小猫捕猎啮齿动物)
- “I like ham sandwiches”(我喜欢火腿三明治)
工作是将具有相似含义的短语分组。对于人类来说,这很容易完成分组。短语 1 和 2 的含义几乎完全相同,而短语 3 的意思完全不同。
短语 1 和 2 将被绘制的位置比较接近,因为它们的含义相似。而短语 3 所在的位置与其他短语的距离较远,因为它与其它短语没有关联。
嵌入的使用
OpenAI使用嵌入可用来干什么
OpenAI 提供 API为文本字符串生成嵌入,最新的嵌入模型 text-embedding-ada-002 支持输出 1536 个维度。OpenAI 的Enmeddings用来衡量文本字符串的相关性;通常用于:
- Search 搜索(结果按与查询字符串的相关性排序)
- Clustering 聚类(文本字符串按相似性分组)
- Recommendations 推荐(推荐具有相关文本字符串的条目)
- Anomaly detection 异常检测(识别出相关性很小的异常值)
- Diversity measurement 多样性测量(分析相似性分布)
- Classification 分类(其中文本字符串按其最相似的标签分类)
为什么OpenAI要使用嵌入
Token的限制;提示和结果必须在约定的token数量之类。如果需要回答自定义的知识库的内容可能会超出限制;而每次提问都携带知识库等内容,也是一种浪费。
借助 OpenAI 将自定义知识库生成嵌入并保存到数据库,然后将提示分为两个阶段来帮助解决这个问题:
- 查询您的嵌入数据库,寻找与问题相关的最相关文档。
- 将这些文档作为上下文注入到 GPT-3 中,让它在回答中引用。
这样处理之后,OpenAI 不仅会返回现有的文档,它还能将各种信息融合为一个连贯的答案。整个问题的处理流程可能如下所示:
- 预处理知识库,并为每个知识库文档页面生成嵌入
- 存储嵌入以备以后使用(更多信息)
- 构建一个搜索页面来提示用户输入
- 获取用户输入,生成一次性嵌入,然后对已预处理的嵌入执行相似性搜索。
- 将嵌入和搜索的问题提交给 ChatGPT,并将最终内容返回给用户。
目前已经有牛人推出了开源项目GitHub – supabase-community/nextjs-openai-doc-search: Template for building your own custom ChatGPT ;基于此可快速搭建一套AI文档系统。
在自建知识库中应用,通过将文本转化为嵌入向量的形式,利用嵌入 OpenAI 可以对自建知识库中的文本进行自动分类和标签生成,从而更好地组织文件和资源;搭配 OpenAI 的问答系统可以根据用户的提问,从自建知识库中智能查找相关信息并给出回答。
本系列的所有文章: