非线性假设Non-linear Hypotheses
非线性假设(Non-linear Hypotheses)是指机器学习模型中假设函数不仅仅是线性的,而是可以表示为非线性函数的情况。在非线性假设下,模型可以更灵活地捕捉数据中的复杂关系和模式,从而提高模型的预测能力。
线性假设是指假设函数可以表示为输入特征的线性组合,例如 h_θ(x)=θ0+θ_1x_1+θ_2x_2+…。然而,很多真实世界的问题并不具备线性关系。例如,在图像识别、自然语言处理和复杂物理问题中,数据往往呈现出复杂的非线性模式。
为了能够应对这些问题,引入了非线性假设。非线性假设可以通过在模型中引入非线性函数,如指数函数、多项式函数、Sigmoid函数、ReLU函数等,来更好地拟合数据中的非线性模式。这使得模型可以在更抽象和复杂的特征空间中进行学习,从而更准确地预测新的数据。
非线性假设的作用包括:
- 更好的拟合数据: 在许多现实问题中,数据并不符合线性关系。引入非线性假设可以使模型更适应复杂的数据模式,从而提高预测的准确性。
- 捕捉更高级的特征: 非线性假设允许模型通过引入非线性函数来捕捉更高级、更抽象的特征。这使得模型能够更深入地理解数据的本质。
- 解决复杂问题: 很多问题具有复杂的非线性关系,如图像识别、语音识别等。非线性假设使得模型能够解决这些复杂问题,从而提高了应用的范围。
- 增强泛化能力: 引入适当的非线性假设有助于减小过拟合的风险,因为模型可以更好地捕捉数据中的实际模式,而不是纠缠于噪声。
教程中以非线性假设用来说明,针对一般的逻辑回归来说需要计算的特征太多了。无论是线性回归还是逻辑回归都有这样一个缺点,即:当特征太多时,计算的负荷会非常大。
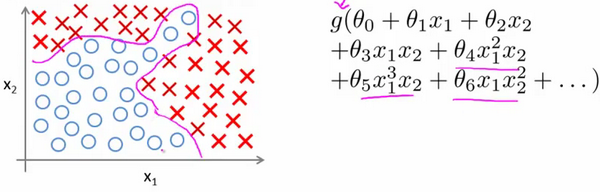
以视觉识别为例,常用方法是利用很多汽车的图片和很多非汽车的图片,然后利用这些图片上一个个像素的值(饱和度或亮度)来作为特征。假如我们只选用灰度图片,每个像素则只有一个值(而非 RGB值),我们可以选取图片上的两个不同位置上的两个像素,然后训练一个逻辑回归算法利用这两个像素的值来判断图片上是否是汽车:
假使我们采用的都是50×50像素的小图片,并且我们将所有的像素视为特征,则会有 2500个特征,如果我们要进一步将两两特征组合构成一个多项式模型,则会有约个(接近3百万个)特征。
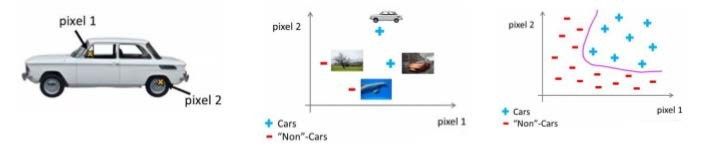
总之,现实中存在太多的非线性的拟合,该计算量过大也过于复杂,传统的算法难以满足需要,神经网络提供了解决的可能。
神经元和大脑Neurons and the Brain
神经网络是一种很古老的算法,它最初产生的目的是制造能模拟大脑的机器。神经网络(Neural Network,简称NN)是一种受到生物神经系统启发而设计的机器学习模型,用于解决各种复杂的任务,如分类、回归、图像处理、自然语言处理等。神经网络的设计灵感来自于人类大脑的神经元网络结构,它由多层神经元节点组成,每层与下一层之间的连接称为权重。
构成
神经网络的主要特点是通过训练,自动地学习输入数据的特征和模式,以便进行准确的预测和分类。它包含多个层次,通常包括以下几种主要层:
- 输入层(Input Layer): 接受原始输入数据,将其传递给下一层。
- 隐藏层(Hidden Layers): 处理输入数据,并通过权重和激活函数的组合来生成更高级的特征表示。网络可以有多个隐藏层,每个层的节点数量和结构可以根据任务和需求进行调整。
- 输出层(Output Layer): 产生最终的模型预测或分类结果。输出层的节点数量通常与问题的类别数相关。
每个节点(也称为神经元)在每一层中都会对上一层的输出应用权重,然后通过激活函数进行非线性变换。激活函数引入非线性性,允许神经网络学习和表示复杂的非线性关系。
架构
神经网络的训练过程通常使用反向传播(Backpropagation)算法,它基于梯度下降法更新权重,以最小化损失函数(代价函数)。反向传播算法计算每个权重对损失函数的影响,然后通过调整权重来减小损失。
一些常见的神经网络架构包括:
- 前馈神经网络(Feedforward Neural Network): 数据从输入层流向输出层,没有反馈连接。多层感知机(Multilayer Perceptron,MLP)是最常见的前馈神经网络。
- 卷积神经网络(Convolutional Neural Network,CNN): 专门用于图像处理和计算机视觉任务,通过卷积层和池化层来捕捉局部特征。
- 循环神经网络(Recurrent Neural Network,RNN): 具有循环连接的神经网络,用于处理序列数据,如自然语言。
- 长短时记忆网络(Long Short-Term Memory,LSTM): 一种特殊的RNN,用于解决序列数据中的梯度消失问题。
- 变换器(Transformer): 用于自然语言处理任务的架构,将注意力机制引入神经网络,具有强大的并行计算能力。
发展
神经网络的发展历史可以追溯到上世纪40年代,经历了多个阶段的演化和发展。以下是神经网络发展的主要历史阶段和重要事件:
- 早期神经元模型(1940s – 1950s): 在20世纪40年代,Warren McCulloch 和 Walter Pitts 提出了一种神经元模型,即McCulloch-Pitts神经元,用于模拟生物神经元的工作原理。这是神经网络的早期基础。
- 感知机的兴起与陨落(1950s – 1960s): Frank Rosenblatt 在1957年提出了感知机模型,它是一种简单的单层神经网络,能够实现二分类任务。然而,1969年,Marvin Minsky 和 Seymour Papert 发表了一本书《Perceptrons》,指出感知机存在一些限制,无法处理某些非线性问题,导致感知机的发展进入了低谷。
- 连接主义研究的复兴(1980s): 在20世纪80年代,神经网络研究重新获得了关注。多层前馈神经网络(多层感知机)的概念重新被提出,且在理论和应用中取得了一些进展,但仍然受到限制。
- 反向传播算法的引入(1980s): 1986年,David Rumelhart、Geoffrey Hinton 和 Ronald Williams 提出了反向传播算法,该算法能够有效地训练多层神经网络,解决了训练难度的问题,为神经网络的发展开辟了新的道路。
- 卷积神经网络(1990s – 2000s): 1998年,Yann LeCun 等人引入了卷积神经网络(CNN),并在手写数字识别任务上取得了显著的成果。CNN 的提出对图像处理领域产生了深远的影响。
- 深度学习的崛起(2010s至今): 进入2010年代,随着大数据和计算能力的提升,以及更好的算法和架构设计,深度学习(Deep Learning)迅速崛起。深度学习包括多层神经网络,如深层卷积神经网络、循环神经网络(RNN)以及Transformer等,取得了在计算机视觉、自然语言处理等领域的重大突破,包括图像分类、语义分割、机器翻译、语音识别等。
- 大规模模型和应用扩展(2020s): 随着技术的不断进步,如强化学习、生成对抗网络(GANs)、自监督学习等的发展,以及更大规模的计算能力和数据集,神经网络在各个领域不断取得突破,如自动驾驶、医疗诊断、金融分析等。
优势
神经网络相比于逻辑回归和线性回归的一些优势:
| 特点 / 方法 | 逻辑回归和线性回归 | 神经网络 |
| 模型复杂度 | 简单 | 可以非常复杂,适应多种任务 |
| 特征表示能力 | 有限 | 强大,可以捕捉复杂的特征 |
| 非线性关系建模 | 有限 | 可以捕捉非线性关系 |
| 数据维度 | 适用于低维数据 | 适用于高维和复杂数据 |
| 特征工程需求 | 较多 | 部分特征工程,自动学习特征 |
| 模型泛化能力 | 有限 | 高,通过深层结构提高泛化性能 |
| 训练复杂性 | 简单 | 复杂,需要更多计算资源 |
| 任务范围 | 适用于简单任务 | 适用于复杂任务和大数据 |
模型表示1 Model Representation I
每一个神经元都可以被认为是一个处理单元/神经核(processing unit/Nucleus),它含有许多输入/树突(input/Dendrite),并且有一个输出/轴突(output/Axon)。神经网络是大量神经元相互链接并通过电脉冲来交流的一个网络。
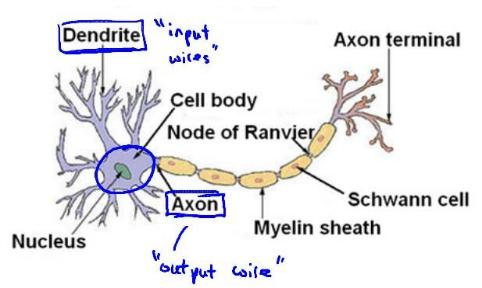
神经元利用微弱的电流进行沟通。这些弱电流也称作动作电位,其实就是一些微弱的电流。所以如果神经元想要传递一个消息,它就会就通过它的轴突,发送一段微弱电流给其他神经元,这就是轴突。
神经网络模型建立在很多神经元之上,每一个神经元又是一个个学习模型。这些神经元(也叫激活单元,activation unit)采纳一些特征作为输出,并且根据本身的模型提供一个输出。下图是一个以逻辑回归模型作为自身学习模型的神经元示例,在神经网络中,参数又可被成为权重(weight)。
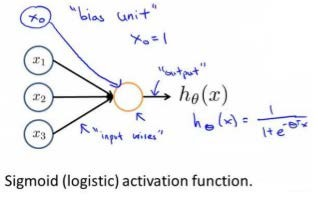
其中x_1,x_2 ,x_3 是输入单元(input units),我们将原始数据输入给它们。 α_1,α_2 ,α_3 是中间单元,它们负责将数据进行处理,然后呈递到下一层。 最后是输出单元,它负责计算h_θ(x)。
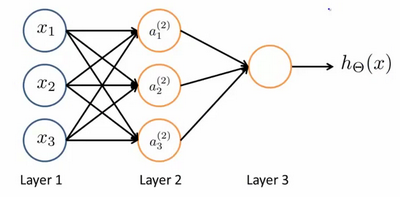
神经网络模型是许多逻辑单元按照不同层级组织起来的网络,每一层的输出变量都是下一层的输入变量。下图为一个3层的神经网络,第一层成为输入层(Input Layer),最后一层称为输出层(Output Layer),中间一层成为隐藏层(Hidden Layers)。我们为每一层都增加一个偏差单位(bias unit):
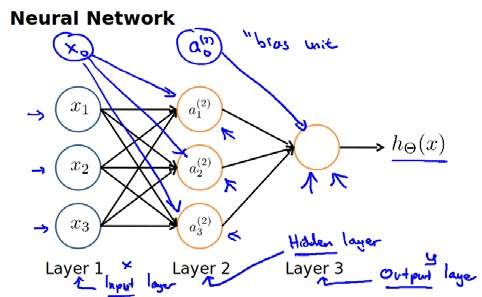

每一个α都是由上一层所有的x和每一个所对应的θ决定的;这样从左到右的算法称为前向传播算法( FORWARD PROPAGATION )。
模型表示2 Model Representation II
( FORWARD PROPAGATION ) 相对于使用循环来编码,利用向量化的方法会使得计算更为简便。以上面的神经网络为例,试着计算第二层的值:
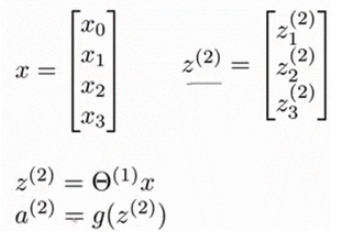


为了更好了了解Neuron Networks的工作原理,我们先把左半部分遮住:
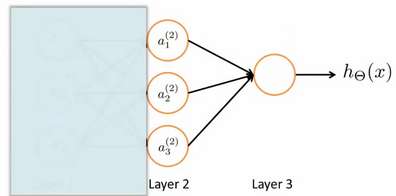
右半部分其实就是以α_0,α_1,α_2,α_3, 按照Logistic Regression的方式输出h_θ(x):
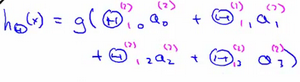
其实神经网络就像是logistic regression,只不过我们把logistic regression中的输入向量 [x1 ~ x3] 变成了中间层的
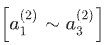
, 即:
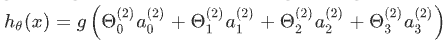
我们可以把α_0,α_1,α_2,α_3看成更为高级的特征值,也就是x_0,x_1,x_2,x_3的进化体,并且它们是由x与θ决定的,因为是梯度下降的,所以是变化的,并且变得越来越厉害,所以这些更高级的特征值远比仅仅将 x次方厉害,也能更好的预测新数据。 这就是神经网络相比于逻辑回归和线性回归的优势。
特征和直观理解1 Examples and Intuitions I
从本质上讲,神经网络能够通过学习得出其自身的一系列特征。
神经网络中,单层神经元(无中间层)的计算可用来表示逻辑运算,比如逻辑与(AND)、逻辑或(OR)。
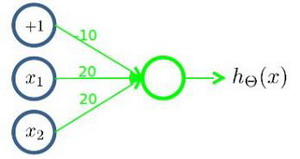
一个神经网络表示AND 函数
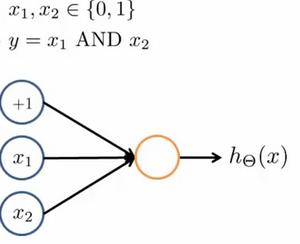
其中 θ_0=-30, θ_1=20, θ_2=20,我们的输出函数h_θ(x)即为:h_θ(x)=g(-30+20x_1+20x_2)
我们知道的g(x)图像是:
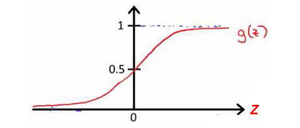

所以h_θ(x)≈x_1 AND x_2,这就是AND函数
一个神经网络标识OR函数
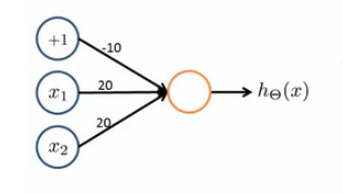
其中 θ_0=-10, θ_1=20, θ_2=20,我们的输出函数h_θ(x)即为:h_θ(x)=g(-10+20x_1+20x_2)
我们知道的g(x)图像是:
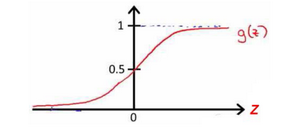

所以h_θ(x)≈x_1 OR x_2,这就是OR函数
样本和直观理解II Examples and Intuitions II
二元逻辑运算符(BINARY LOGICAL OPERATORS)当输入特征为布尔值(0或1)时,可以用一个单一的激活层可以作为二元逻辑运算符,为了表示不同的运算符,我们只需要选择不同的权重即可。
下图的神经元(三个权重分别为-30,20,20)可以被视为作用同于逻辑与(AND):
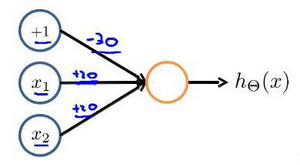
下图的神经元(三个权重分别为-10,20,20)可以被视为作用等同于逻辑或(OR):
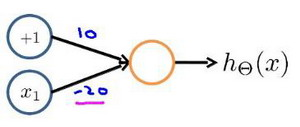
下图的神经元(两个权重分别为 10,-20)可以被视为作用等同于逻辑非(NOT):
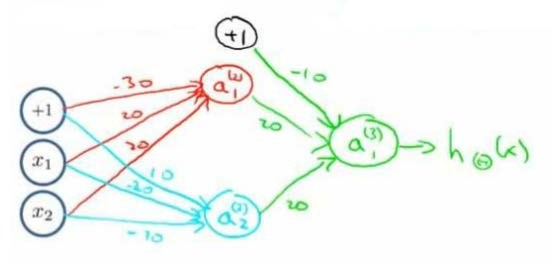
利用神经元来组合成更为复杂的神经网络以实现更复杂的运算:实现XNOR 功能(输入的两个值必须一样,均为1或均为0),即 XNOR=(x_1 AND x_2) OR ((NOT x_1) AND (NOT x_2) ).
- 首先构造一个能表达(NOT x_1) AND (NOT x_2)部分的神经元:
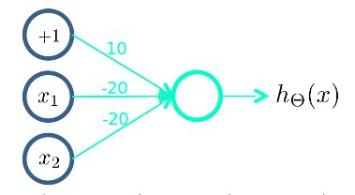
- 然后将表示 AND 的神经元和表示(NOT x_1) AND (NOT x_2)的神经元以及表示 OR 的神经元进行组合:
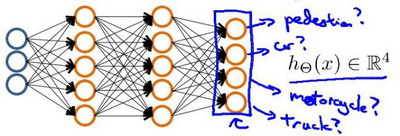
多类分类 Multiclass Classification
通常分类会有不止两种分类,比如训练一个神经网络算法来识别路人、汽车、摩托车和卡车,在输出层我们应该有4个值,分别与分类对应。
输入向量x有三个维度,两个中间层,输出层4个神经元分别用来表示4类,也就是每一个数据在输出层都会出现 [a b c d]^T ,且 a,b,c,d中仅有一个为1表示当前类。
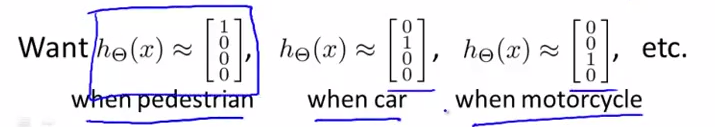
神经网络算法的输出结果为四种可能情形之一:
