决定下一步做什么 Deciding What to Try Next
当训练好了的模型来预测未知数据的时候发现有较大的误差,下一步一般有以下动作:
- 获得更多的训练样本——通常是有效的,但代价较大,下面的方法也可能有效,可考虑先采用下面的几种方法;
- 尝试减少特征的数量
- 尝试获得更多的特征
- 尝试增加多项式特征
- 尝试减少正则化程度
- 尝试增加正则化程度
不应该随机选择上面的某种方法来改进算法,而是运用一些机器学习诊断法来帮助知道上面哪些方法对算法是有效的。"机器学习诊断法":这是一种测试法,通过执行测试,能够深入了解某种算法到底是否有用。这通常也能够告诉你,要想改进一种算法的效果,什么样的尝试,才是有意义的。
评估一个假设 Evaluating a Hypothesis
当确定算法的参数的时候,希望是选择参量来使训练误差最小化;但是当假设具有很小的训练误差,并不能说明它就一定是一个好的假设函数。比如过拟合假设函数,当推广到新的训练集上却是不适用的。
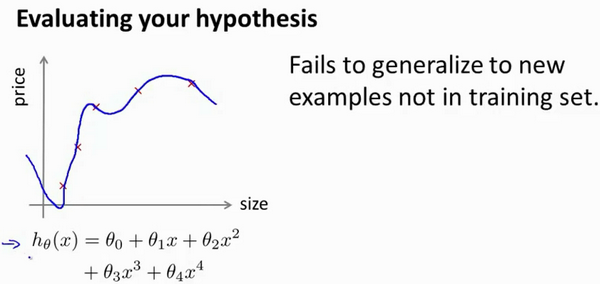
如何判断一个假设函数是过拟合的呢?
可以对假设函数进行画图,然后观察图形趋势,但对于特征变量不止一个的这种一般情况,还有像有很多特征变量的问题,想要通过画出假设函数来进行观察,就会变得很难甚至是不可能实现。 因此,我们需要另一种方法来评估我们的假设函数过拟合检验。
为了检验算法是否过拟合,我们将数据分成训练集和测试集,通常用70%的数据作为训练集,用剩下30%的数据作为测试集。很重要的一点是训练集和测试集均要含有各种类型的数据,通常我们要对数据进行“洗牌”,然后再分成训练集和测试集。
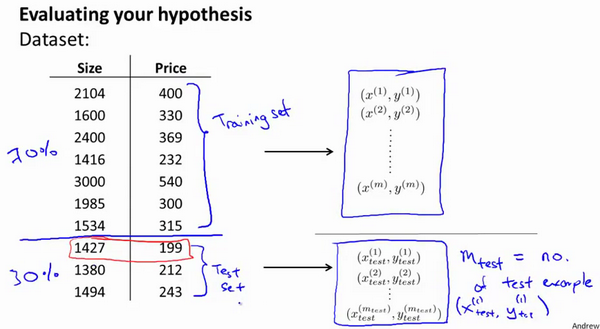
测试集评估在通过训练集让我们的模型学习得出其参数后,对测试集运用该模型,我们有两种方式计算误差:
- 对于线性回归模型,我们利用测试集数据计算代价函数J
- 对于逻辑回归模型,我们除了可以利用测试数据集来计算代价函数外:
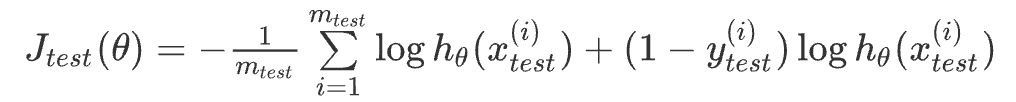
误分类的比率,对于每一个测试集样本,计算:
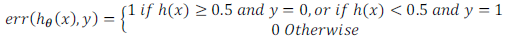
然后对计算结果求平均。
过拟合的判断处理
为了检验算法是否过拟合,我们将数据分成训练集和测试集。通常,我们会使用70%的数据作为训练集,剩下的30%作为测试集。
- 训练集(70%):这部分数据用于训练模型,使其学习到输入与输出之间的关系。
- 测试集(30%):这部分数据用于评估模型在未见过的数据上的表现,从而检验是否发生过拟合。
过拟合是指模型在训练集上表现得很好,但在测试集(即未曾见过的数据)上表现较差。这意味着模型过于复杂,捕捉到了训练数据中的噪声,而非真实的底层关系。为了避免过拟合,可以采取以下策略:
- 收集更多的数据
- 使用简单的模型
- 降低模型的复杂度
- 采用正则化技术
- 交叉验证
模型选择和交叉验证集Model Selection and Train_Validation_Test Sets
假设在10个不同次数的二项式模型之间进行选择:
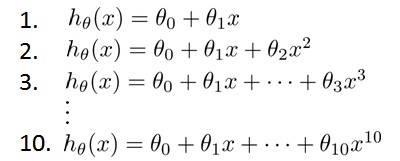
显然越高次数的多项式模型越能够适应我们的训练数据集,但是适应训练数据集并不代表着能推广至一般情况,应该选择一个更能适应一般情况的模型。
交叉验证:
使用60%的数据作为训练集,使用 20%的数据作为交叉验证集,使用20%的数据作为测试集
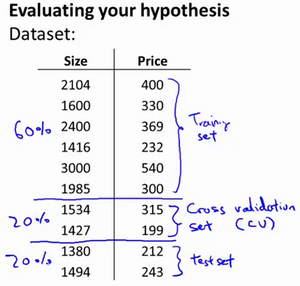
模型选择的方法为:

- 使用训练集训练出10个模型
- 用10个模型分别对交叉验证集计算得出交叉验证误差(代价函数的值)
- 选取代价函数值最小的模型
- 用步骤3中选出的模型对测试集计算得出推广误差(代价函数的值)
交叉验证是一种常用的模型选择和调优技术,可以帮助评估模型的性能并选择合适的超参数。
- 数据集划分:将数据集分为训练集、交叉验证集和测试集。
- 模型训练:使用训练集来训练多个不同的模型,可以是不同类型的模型或者具有不同超参数的同类型模型。
- 交叉验证:对于每个训练好的模型,在交叉验证集上进行训练验证。对每次交叉验证计算模型的性能指标,如准确率、准确率、响应率等。
- 模型选择和超参数调优:根据交叉验证的结果,选择表现最好的模型。这可以基于平均性能指标,例如平均准确率。如果您的模型有超参数(例如隐藏神经网络的层大小、学习率等),可以使用交叉验证来调节优超参数。尝试不同的超参数组合,并选择在交叉验证集上表现最好的组合。
- 最终测试:选定模型和超参数后,使用测试集来进行最终的模型评估。
需要注意的是,交叉验证和测试集的划分应该是单次随机进行的,以保证结果的可靠性。同时,交叉验证能够更好地利用数据,减少模型评估的偶然性,提供更稳定的性能估计。
诊断偏差和方差Diagnosing Bias vs. Variance
如果算法的表现不理想,那么多半是出现两种情况:要么是偏差比较大,要么是方差比较大。换句话说,出现的情况要么是欠拟合,要么是过拟合问题。
偏差(Bias): 偏差是模型对真实关系的错误假设,通常导致模型无法捕捉数据中的复杂性。高偏差意味着模型过于简单,无法适应数据的细节,可能会导致欠拟合。在训练集上表现不佳的模型通常具有较高的偏差。
方差(Variance): 方差是模型对训练数据中噪声的敏感程度,即模型对于输入数据的小变化非常敏感。高方差意味着模型过于复杂,学习了数据的噪声,从而导致在新数据上的表现较差,即过拟合。
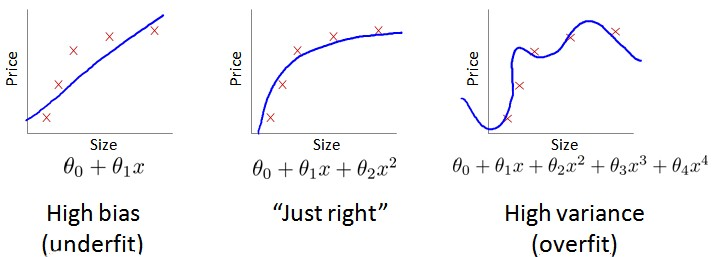
通常会通过将训练集和交叉验证集的代价函数误差与多项式的次数绘制在同一张图表上来帮助分析:
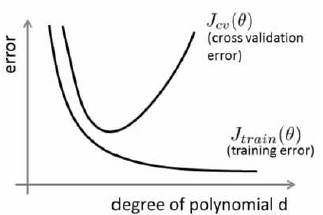

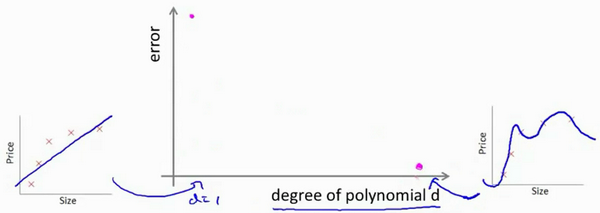
对于训练集,当 d 较小时,模型拟合程度更低,误差较大;随着 d 的增长,拟合程度提高,误差减小。 对于交叉验证集,当 d 较小时,模型拟合程度低,误差较大;但是随着 d 的增长,误差呈现先减小后增大的趋势,转折点是我们的模型开始过拟合训练数据集的时候。 如果我们的交叉验证集误差较大,我们如何判断是方差还是偏差呢?根据上面的图表,我们知道:
训练集误差和交叉验证集误差近似时:偏差/欠拟合
交叉验证集误差远大于训练集误差时:方差/过拟合
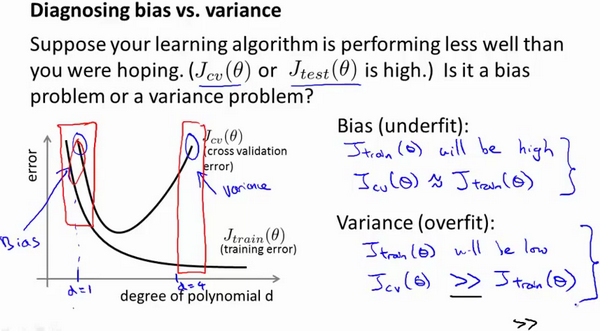
诊断偏差和方差是在机器学习模型中评估性能和调整模型的重要步骤。偏差和方差是两种不同的错误来源,可以帮助你理解模型在训练数据上的表现以及是否过度拟合或欠拟合。以下是诊断偏差和方差的一般步骤
- 训练误差和验证误差: 训练模型并分别计算训练误差(在训练集上的误差)和验证误差(在验证集上的误差)。
- 偏差检查: 如果训练误差和验证误差都很高,说明模型可能存在偏差问题。这表示模型无法捕捉数据中的模式,可能需要增加模型的复杂性,例如使用更多的特征、更复杂的模型结构等。
- 方差检查: 如果训练误差很低,但验证误差很高,说明模型可能存在方差问题。这表示模型对训练数据的小变化非常敏感,可能需要减少模型的复杂性,进行正则化,或者增加更多的训练数据。
- 偏差-方差权衡: 在调整模型时,要平衡偏差和方差。过于简单的模型会导致偏差高,而过于复杂的模型会导致方差高。需要找到一个合适的模型复杂度,使得在验证集上达到较低的总误差。
总之,诊断偏差和方差是优化机器学习模型的关键步骤。通过理解模型在训练数据和验证数据上的表现,可以选择适当的调整来改善模型的泛化能力。
正则化和偏差/方差Regularization and Bias_Variance
正则化是一种用于控制模型复杂性以及减少过拟合(高方差)的技术,与偏差-方差问题密切相关。它是在训练过程中向模型的损失函数中添加一个惩罚项,以限制模型权重的大小,从而使模型更倾向于学习一般的模式,而不是训练数据中的噪声。正则化有助于在偏差和方差之间找到平衡点,从而提高模型的泛化能力。
有两种常见的正则化技术:L1 正则化(Lasso 正则化)和 L2 正则化(Ridge 正则化)。它们分别通过在损失函数中添加权重的绝对值和平方项来实现正则化。
与偏差-方差问题的关系:
- 偏差问题: 当模型存在高偏差(即无法捕捉数据中的复杂性)时,可以尝试降低正则化的程度,以允许模型更好地拟合训练数据。过多的正则化可能会限制模型学习能力,导致欠拟合。
- 方差问题: 当模型存在高方差(即对训练数据非常敏感)时,可以增加正则化的程度,限制模型的复杂性。正则化可以减少模型对训练数据中噪声的过度拟合,从而降低方差。
在实际应用中,可以通过调整正则化参数来平衡偏差和方差。较大的正则化参数会减小权重的影响,从而降低模型的复杂性;较小的正则化参数允许模型更灵活地适应数据。通过在交叉验证中尝试不同的正则化参数值,可以找到适合数据的最佳平衡点,从而改善模型性能。
在训练模型的过程中,一般会使用一些正则化方法来防止过拟合。但是我们可能会正则化的程度太高或太小了,即我们在选择λ的值时也需要思考与刚才选择多项式模型次数类似的问题。
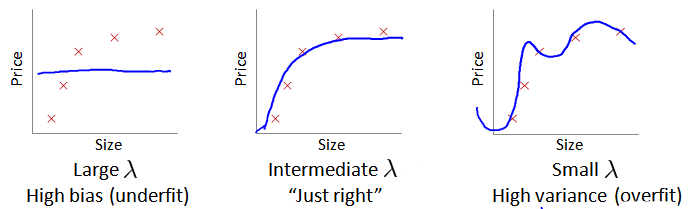
选择一系列的想要测试的λ值,通常是 0-10之间的呈现2倍关系的值(如:0,0.01,0.02,0.04,0.08,0.16等共12个)。 我们同样把数据分为训练集、交叉验证集和测试集。


选择的方法为:
- 使用训练集训练出12个不同程度正则化的模型
- 用12个模型分别对交叉验证集计算的出交叉验证误差
- 选择得出交叉验证误差最小的模型
- 运用步骤3中选出模型对测试集计算得出推广误差,我们也可以同时将训练集和交叉验证集模型的代价函数误差与λ的值绘制在一张图表上:当λ较小时,训练集误差较小(过拟合)而交叉验证集误差较大 • 随着λ的增加,训练集误差不断增加(欠拟合),而交叉验证集误差则是先减小后增加
学习曲线Learning Curves
学习曲线是用于评估机器学习模型性能和诊断偏差-方差问题的有用工具。它展示了模型在不同训练数据量下的训练误差和验证误差之间的关系。通过观察学习曲线,你可以更好地理解模型在不同数据规模和复杂性下的表现。
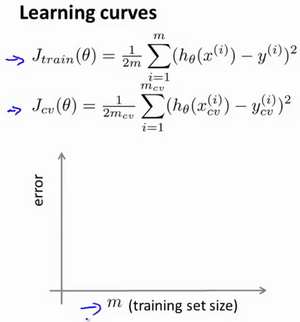
学习曲线是学习算法的一个很好的合理检验(sanity check)。学习曲线是将训练集误差和交叉验证集误差作为训练集样本数量(m)的函数绘制的图表。 即,如果我们有100行数据,我们从1行数据开始,逐渐学习更多行的数据。思想是:当训练较少行数据的时候,训练的模型将能够非常完美地适应较少的训练数据,但是训练出来的模型却不能很好地适应交叉验证集数据或测试集数据。
学习曲线通常具有以下特点:
- 小数据量下的学习曲线: 当使用少量数据进行训练时,模型容易过度拟合(高方差)。在这种情况下,训练误差会很低,但验证误差会很高,因为模型无法很好地泛化到新数据。
- 逐渐增加数据量: 随着使用更多数据进行训练,模型可能开始更好地捕捉数据中的模式,验证误差逐渐下降。此时,训练误差和验证误差之间的差距逐渐减小。
- 饱和点: 在某个点之后,继续增加训练数据可能不会显著改善模型的性能。训练误差和验证误差会趋于稳定,这是因为模型已经能够从数据中学到大部分的模式。
学习曲线的不同形状可以提示你关于模型的信息:
- 高偏差: 如果训练误差和验证误差都很高,且它们之间的差距不大,说明模型可能存在高偏差问题。这表示模型无法很好地适应数据,可能需要更复杂的模型或更多的特征。
- 高方差: 如果训练误差很低,但验证误差很高,且它们之间的差距较大,说明模型可能存在高方差问题。这表示模型对训练数据过于敏感,需要更多的训练数据或者正则化来减少过拟合。
学习曲线的绘制可以通过以下步骤完成:
- 将不同大小的训练数据分别用于训练和验证模型。
- 计算每个数据量下的训练误差和验证误差。
- 绘制学习曲线图,横轴表示训练数据量,纵轴表示误差。
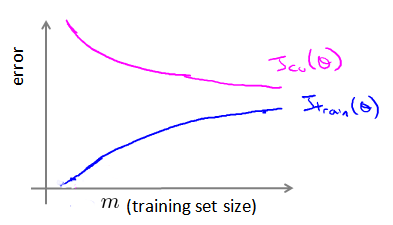
利用学习曲线识别高偏差/欠拟合
作为例子,我们尝试用一条直线来适应下面的数据,可以看出,无论训练集有多么大误差都不会有太大改观:
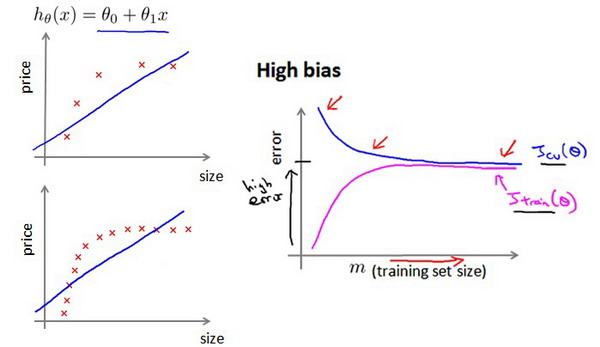
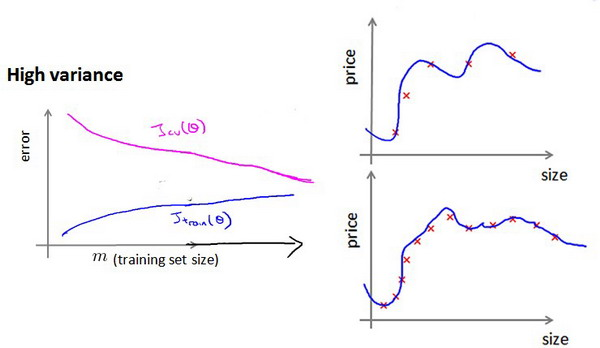
也就是说在高偏差/欠拟合的情况下,增加数据到训练集不一定能有帮助。 如何利用学习曲线识别高方差/过拟合:假设我们使用一个非常高次的多项式模型,并且正则化非常小,可以看出,当交叉验证集误差远大于训练集误差时,往训练集增加更多数据可以提高模型的效果。
也就是说在高方差/过拟合的情况下,增加更多数据到训练集可能可以提高算法效果。
决定下一步做什么Deciding What to Do Next Revisited
当训练好了的模型来预测未知数据的时候发现有较大的误差,下一步一般有以下动作:
- 获得更多的训练样本——解决高方差
- 尝试减少特征的数量——解决高方差
- 尝试获得更多的特征——解决高偏差
- 尝试增加多项式特征——解决高偏差
- 尝试减少正则化程度λ——解决高偏差
- 尝试增加正则化程度λ——解决高方差
神经网络的方差和偏差:
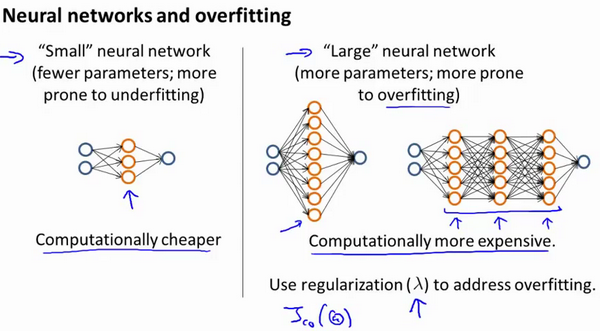
使用较小的神经网络,类似于参数较少的情况,容易导致高偏差和欠拟合,但计算代价较小使用较大的神经网络,类似于参数较多的情况,容易导致高方差和过拟合,虽然计算代价比较大,但是可以通过正则化手段来调整而更加适应数据。 通常选择较大的神经网络并采用正则化处理会比采用较小的神经网络效果要好。 对于神经网络中的隐藏层的层数的选择,通常从一层开始逐渐增加层数,为了更好地作选择,可以把数据分为训练集、交叉验证集和测试集,针对不同隐藏层层数的神经网络训练神经网络, 然后选择交叉验证集代价最小的神经网络。