支持向量机(Support Vector Machine,SVM)是一种机器学习算法,用于分类和回归分析。它是一种监督学习方法,最初由Vladimir Vapnik等人于20世纪90年代开发。
SVM 的主要目标是找到一个能够将不同类别的数据点分隔开的超平面(在二维空间中,超平面就是一条直线)。这个超平面被选择为使两个不同类别的数据点距离超平面的间隔最大化。这些距离称为支持向量,因此 SVM 的名字就来源于此。
以下是 SVM 的关键概念和工作原理:
- 超平面:在二维空间中,超平面是一条直线,但在高维空间中,它是一个超平面。SVM 的目标是找到一个能够最大化不同类别数据点到这个超平面的距离的超平面。
- 支持向量:支持向量是离超平面最近的那些数据点。它们是决定超平面位置的关键元素。
- 分类:SVM 可以用于二元分类和多元分类问题。在二元分类中,SVM试图找到一个超平面,将数据点分为两个类别。在多元分类中,SVM 可以通过多个超平面的组合来实现。
- 核函数:SVM 可以使用核函数来处理线性不可分的数据。核函数将数据映射到高维空间,使其在高维空间中线性可分。常用的核函数包括线性核、多项式核和高斯核(RBF核)等。
- 正则化:SVM 通常使用正则化来避免过拟合。正则化参数可以调整模型的复杂度,以提高泛化性能。
优化目标 Optimization Objective
与逻辑回归和神经网络相比,支持向量机,或者简称SVM,在学习复杂的非线性方程时提供了一种更为清晰,更加强大的方式。从逻辑回归开始展示如何一点一点修改来得到本质上的支持向量机。
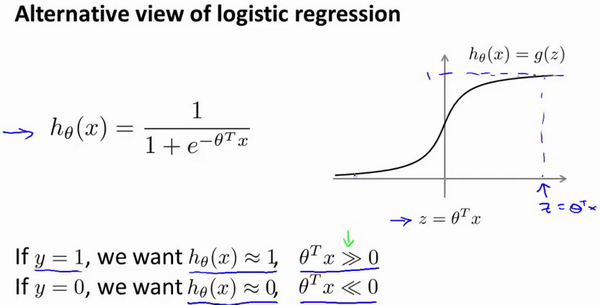
当h_θ(x)=g(z)无限趋近于1,则

反之,则其远小于0
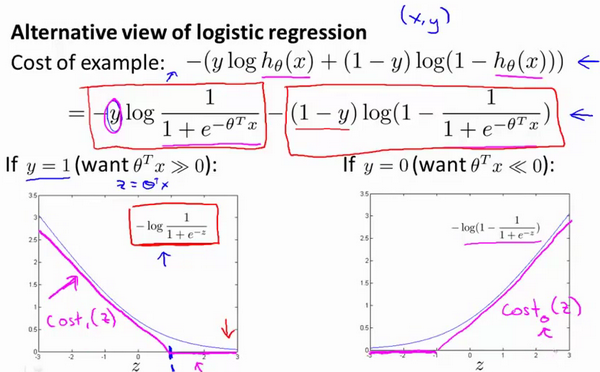
将上述带入代价函数,得到该公式;一般分两种情况,一种是y=0,另一种是y=1。所以会得到两个简化的代价函数。
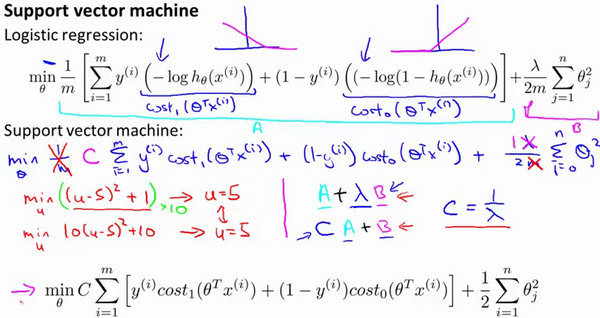
两种情况表达起来仍然还是会比较困难,所以用一个新的代价函数来代替。
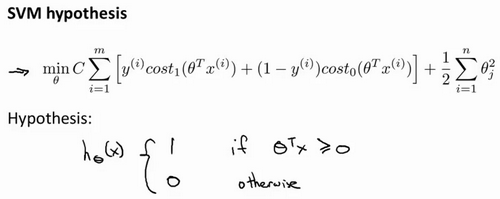
大边界的直观理解 Large Margin Intuition
人们有时也将支持向量机看作是大间距分类器;以下是支持向量机模型的代价函数。

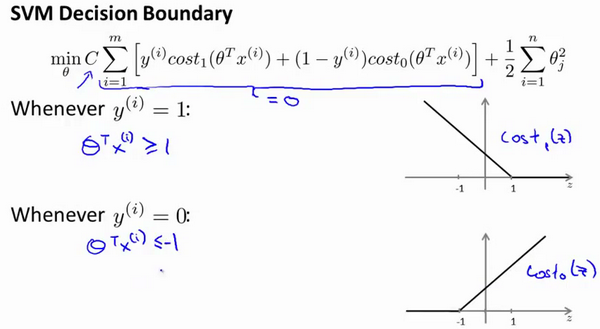
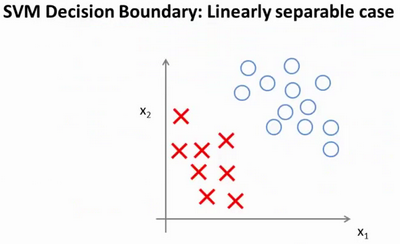
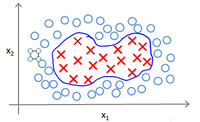
具体而言,如果数据集有正样本,也有负样本,可以看到这个数据集是线性可分的。存在一条直线把正负样本分开。当然有多条不同的直线,可以把正样本和负样本完全分开。这就是一个决策边界可以把正样本和负样本分开。

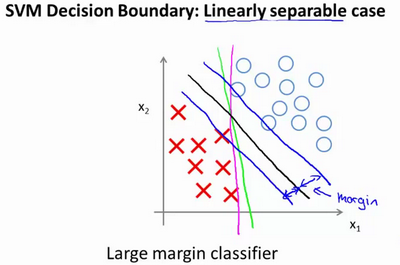
或者可以画一条更差的决策界,这是另一条决策边界,可以将正样本和负样本分开,但仅仅是勉强分开,这些决策边界看起来都不是特别好的选择,支持向量机将会选择这个黑色的决策边界,相较于之前用粉色或者绿色画的决策界。这条黑色的看起来好得多,黑线看起来是更稳健的决策界。在分离正样本和负样本上它显得的更好。数学上来讲,黑线有更大的距离,这个距离叫做间距(margin)。
当画出这两条额外的蓝线,黑色的决策界和训练样本之间有更大的最短距离。而粉线和蓝线离训练样本就非常近,在分离样本的时候就会比黑线表现差。因此,这个距离叫做支持向量机的间距,而这是支持向量机具有鲁棒性的原因,因为它努力用一个最大间距来分离样本。因此支持向量机有时被称为大间距分类器。
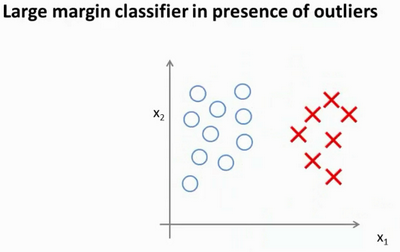
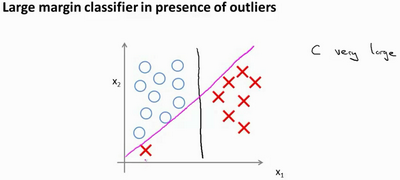
如果将公式中的C设置的不要太大,则最终会得到这条黑线;当C不是非常非常大的时候,它可以忽略掉一些异常点的影响,得到更好的决策界。回顾 C=1/λ,因此:
- C较大时,相当于 λ 较小,可能会导致过拟合,高方差。
- C较小时,相当于 λ 较大,可能会导致低拟合,高偏差。
核函数 Kernels
核函数是在支持向量机(SVM)和其他一些机器学习算法中使用的重要概念之一。核函数允许算法在高维特征空间中进行非线性映射,从而使本来线性不可分的数据变得线性可分。这种技术特别有助于处理复杂的非线性问题。
核函数的主要作用是将输入数据从原始特征空间映射到更高维的特征空间,使数据在新的空间中变得线性可分。这有助于在高维空间中找到一个超平面,以最佳方式分离不同类别的数据点。核函数是通过以下方式实现的:
- 线性核(Linear Kernel):这是最简单的核函数,它不进行任何映射,直接在原始特征空间中执行计算。线性核适用于线性可分的情况。
- 多项式核(Polynomial Kernel):多项式核将数据映射到高维空间,通过多项式函数来实现。核函数的参数包括多项式的次数和系数。它适用于一些复杂的非线性问题。
- 高斯核(Gaussian Kernel 或 RBF Kernel):高斯核是最常用的核函数之一。它将数据映射到无穷维的空间,通过指数函数来实现。高斯核的参数是带宽(bandwidth)或标准差。它在处理非线性问题时非常有效。
- Sigmoid核(Sigmoid Kernel):Sigmoid核通过类似于激活函数的方式将数据映射到高维空间。它在某些特定情况下有用,但一般来说不太常用。
选择核函数取决于问题的性质和数据的分布。有时,你需要尝试不同的核函数和参数,以确定哪一个最适合你的数据和任务。
SVM和其他使用核函数的机器学习算法的主要优点之一是,它们可以处理非线性问题,而不需要显式地对数据进行高维映射,从而减少了计算复杂性。核函数的使用使得这些算法在实践中非常强大且灵活。

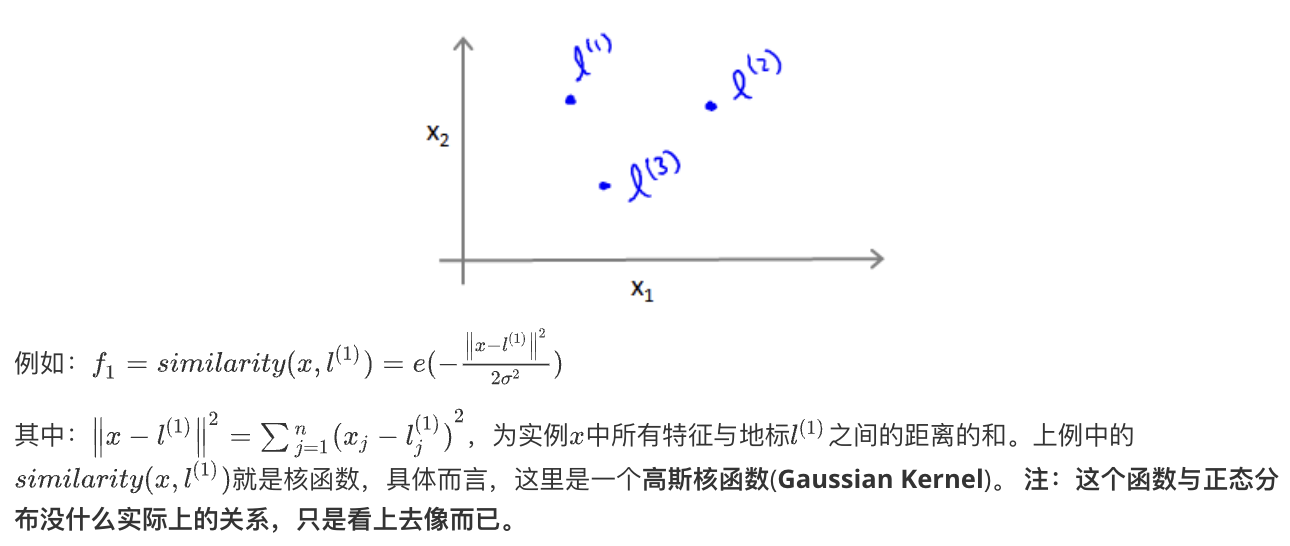

使用支持向量机 Using An SVM
有许多好的软件库,如liblinear和libsvm,可以直接被用来计算。核函数需要满足Mercer’s定理,才能被支持向量机的优化软件正确处理。
Mercer’s 定理是与核函数和正定核(positive definite kernel)有关的数学定理。这个定理的名称来源于数学家 Jesse Mercer,他在20世纪初提出了这个定理。Mercer’s 定理在支持向量机(SVM)和其他机器学习算法中的核方法中起着重要作用。
Mercer’s 定理的主要内容是:
如果一个函数 K(x, y) 在定义域上是对称的(即 K(x, y) = K(y, x))且对于所有可能的输入数据集 {x1, x2, …, xn},矩阵(Gram 矩阵)K_ij = K(xi, xj) 是半正定的,那么这个函数 K(x, y) 就是一个正定核函数。
这个定理的要点是,一个函数如果满足 Mercer’s 定理的条件,就可以作为核函数用于 SVM 或其他基于核方法的机器学习算法中。正定核函数具有一些重要的性质,它们允许将数据映射到高维特征空间,并确保在该空间中的内积(点积)仍然是非负的,从而使 SVM 等算法能够正常运行。
多类分类问题
假设利用之前介绍的一对多方法来解决一个多类分类问题。如果一共有k个类,则我们需要k个模型,以及k个参数向量θ。同样也可以训练k个支持向量机来解决多类分类问题。大多数支持向量机软件包都有内置的多类分类功能,直接使用即可,但需要做几件事:
- 参数C的选择。
- 选择内核参数或你想要使用的相似函数,其中一个选择是:我们选择不需要任何内核参数,没有内核参数的理念,也叫线性核函数。因此,如果有人说使用了线性核的SVM(支持向量机),这就意味这使用了不带有核函数的SVM(支持向量机)。
逻辑回归模型 vs 支持向量机
| 特征 | 逻辑回归模型 | 支持向量机 (SVM) |
| 类型 | 统计模型 | 机器学习模型 |
| 用途 | 二元或多元分类,也可用于概率估计 | 二元或多元分类,也可用于回归 |
| 决策边界 | 线性或非线性,取决于特征和正则化 | 线性或非线性,取决于核函数的选择 |
| 复杂性 | 通常较简单,易于理解和实现 | 可以处理复杂的非线性问题,需要调整参数和核函数 |
| 对特征缩放的敏感性 | 对特征的缩放不太敏感,但通常会受益于特征缩放 | 对特征的缩放敏感,通常需要进行特征缩放 |
| 处理噪声数据的能力 | 对噪声数据相对较为敏感 | 对噪声数据相对较为鲁棒,支持向量起到过滤作用 |
| 解释性 | 提供权重参数,可解释模型的贡献 | 通常不太容易解释,重点在于分类性能 |
| 正则化 | 通过调整正则化参数来控制模型复杂度 | 通过调整 C 参数来控制模型复杂度,也可使用核函数 |
| 训练时间 | 通常较快,适用于大规模数据 | 训练时间可能较长,特别是在大规模数据上 |
| 适用性 | 适用于线性和部分非线性问题 | 适用于线性和非线性问题,对于复杂数据集效果好 |
如何选择上述两类模型:
n为特征数,m为训练样本数。
(1)如果相较于m而言,n要大许多,即训练集数据量不够支持我们训练一个复杂的非线性模型,我们选用逻辑回归模型或者不带核函数的支持向量机。
(2)如果n较小,而且m大小中等,例如n在 1-1000 之间,而m在10-10000之间,使用高斯核函数的支持向量机。
(3)如果n较小,而m较大,例如n在1-1000之间,而m大于50000,则使用支持向量机会非常慢,解决方案是创造、增加更多的特征,然后使用逻辑回归或不带核函数的支持向量机。
值得一提的是,神经网络在以上三种情况下都可能会有较好的表现,但是训练神经网络可能非常慢,选择支持向量机的原因主要在于它的代价函数是凸函数,不存在局部最小值。