内容纲要
导语
复杂任务(长文、代码、策略)很难“一次生成即完美”。反思(Reflection)是把“评估与改进”引入工作流的机制:先产出初稿,再用结构化标准评估,按反馈修订,循环至达标。采用“生产者-评论者”双智能体分工能显著减少偏见、提升客观性,3–5 轮内稳定达到可交付质量。
TL;DR
- 核心:执行→评估/剖析→改进→(必要时)再循环;形成反馈闭环。
- 推荐:双智能体分工(生产者创作、评论者评审),客观且高效。
- 要点:明确评估标准、结构化反馈、设置停止条件、防止无限循环。
- 成本:多轮调用会增加延迟与费用;可限制轮次与上下文长度。
- 协同:与提示链/并行化结合,在关键节点插入“反思检查点”。
- 标志:评论者判定“完美”(<code>CODE_IS_PERFECT</code>)或达到最大轮次即止。
是什么:把“反馈”嵌入到流程里
流程示意:
执行 → 评估/剖析 → 反思/优化 → (必要时)迭代
单智能体:
生成 → 自评 → 改进 → 结束/继续
双智能体:
生产者生成 → 评论者评审 → 生产者改进 → 达标则结束/否则继续可视化(两种模式):
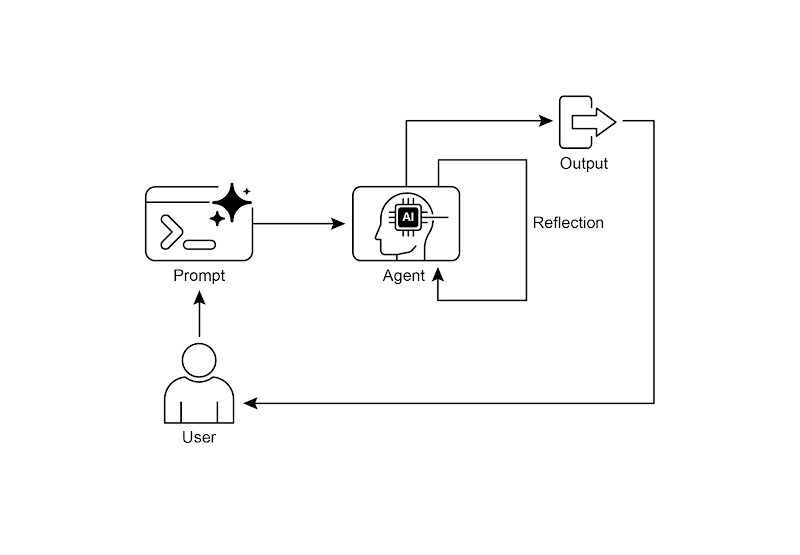
读图要点:单智能体也可反思,但容易“自欺”;效果次优。
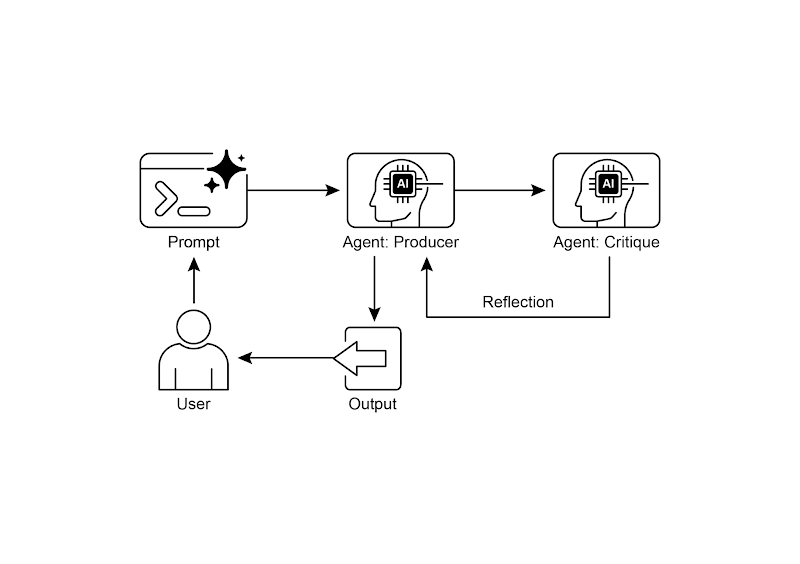
读图要点:生产者专注创作、评论者专注评审;角色分离更客观。
为什么:质量靠反馈闭环而非“一次成活”
- 初稿不可避免存在遗漏/不一致/错误
- 结构化评估标准让“好坏”可被衡量
- 通过外部视角(评论者)减少认知偏见
- 让模型“看到问题—修问题—再确认”,质量自然提高
适用信号:
- 输出质量直接影响业务(代码、事实核查、合规)
- 约束多、难一次到位(风格/事实/结构/边界条件)
- 需要可追溯与可改进的过程记录
怎么做:落地清单
1)定义评估标准与停止条件
- 维度示例:准确性、完整性、风格一致性、可执行性、合规性
- 停止条件:<code>CODE_IS_PERFECT</code>标识位返回、最大 3–5 轮、改进幅度 < 阈值、用户确认
2)结构化反馈
- 用列表/评分/清单输出问题与建议
- 明确“必须修复/建议改进/可忽略”的优先级
3)角色分离:生产者 vs 评论者
- 生产者:生成与修订
- 评论者:审查与建议(避免自己审自己)
4)状态与可观测性
- 记录每轮输入/输出、评估结论、具体改动
- 便于回放、比对提升幅度、进行 A/B
5)成本控制
- 限制轮次与上下文长度
- 小模型做初评,大模型做终审
场景范式
1)创作长文/营销内容
需求 → 生产者写草稿 → 评论者审语气/结构/一致性 → 重写 → 终稿价值:稳定输出高质量文案。
2)代码生成与调试
任务 → 写初版 → 运行测试/静态分析 → 评论者给问题清单 → 修复 → 通过为止价值:更健壮、边界处理完整。
3)复杂问题求解
提出解法 → 评论者找矛盾 → 回退修正 → 直到满足约束价值:减少逻辑错误与幻觉。
对比与取舍
- 优势:质量显著提升、可纠错、可解释、可审计
- 成本:延时与费用增加、上下文更长、实现更复杂
- 取舍:高质量优先时启用反思;简短、低风险任务不必使用
常见错误与排错
- 无明确评估标准 → 结果反复但没有改进方向
- 自评自改 → 偏见难消;建议引入评论者角色
- 无限循环 → 必须设置停止条件与最大轮次
- 上下文爆炸 → 只保留关键反馈与差异,不堆冗余历史
- 成本不可控 → 小模型初评 + 大模型终审,分级把关
FAQ
- 问:一定要双智能体吗?
答:不强制,但双智能体更客观、提升更明显;资源有限可先单体。 - 问:如何设置迭代次数?
答:一般 3–5 轮足够;同时配合“完美信号”与改进阈值。 - 问:和并行化/提示链怎么配合?
答:在提示链关键节点插入反思;或并行生成多个版本,由评论者选择最佳。
延伸阅读与引用
- LangChain LCEL 文档:https://python.langchain.com/docs/introduction/
- LangGraph 反思循环:https://www.langchain.com/langgraph
- Google ADK 多智能体系统:https://google.github.io/adk-docs/agents/multi-agents/
- 自我纠正论文:Training LMs to Self-Correct via RL(2024)
链接:https://arxiv.org/abs/2409.12917
总结
反思不是“锦上添花”,而是让复杂任务“稳定达标”的关键。把评估标准、结构化反馈与停止条件嵌入到流程里,再用生产者-评论者分工去执行,你会发现:质量提升变得可预期、可度量、可复制。把反思作为“质量闸门”,让每次交付都更放心。