1 概述
1.1. 语义搜索
搜索引擎在进行搜索工作时不再局限于用户所输入请求语句的字面本身,而是能够准确地理解用户所输入语句后面的真正意图进行搜索,从而更加准确地返回最符合用户需求的搜索结果。
语义搜索应用用户意图、上下文和概念含义来将用户查询与相应的内容相匹配。它使用矢量搜索和机器学习来返回旨在匹配用户查询的结果,即使没有单词匹配也是如此。
它利用自然语言处理(NLP)和机器学习技术,以便更好地理解文本的语义含义,从而提高搜索的准确性和相关性。
实现语义搜索通常涉及以下步骤:
- 数据准备:首先,您需要有一组文本数据,这可以是文档、网页、产品描述、用户评论或其他文本资源。这些文本数据将用于构建语义搜索引擎的索引。
- 文本预处理:在构建索引之前,文本数据通常需要经过预处理,包括分词、去停用词、词干提取、词义消歧等操作。这有助于将文本数据转换成更容易理解和比较的形式。
- 嵌入(Embedding):将文本数据转换为向量表示是语义搜索的关键步骤。这可以通过使用词嵌入(Word Embeddings)技术,如Word2Vec、GloVe、FastText,或者更高级的语言模型,如BERT、GPT来实现。这些向量表示捕捉了文本的语义信息,使得文本之间的相似性可以通过向量之间的距离来度量。
- 构建索引:一旦您有了文本数据的向量表示,您可以使用一种向量索引技术来加速相似性搜索。流行的向量索引库包括Faiss、Milvus、Annoy等,它们支持高效的向量搜索和检索。
- 查询理解:当用户发起搜索查询时,搜索引擎需要理解用户的查询意图。这可以通过NLP技术来实现,包括命名实体识别、词性标注、语法分析等。这有助于搜索引擎更好地理解用户的问题。
- 检索:使用用户查询的向量表示与索引中的文本向量进行比较,以找到与查询最相关的文本数据。通常,检索可以采用余弦相似性等度量来计算向量之间的相似性得分,然后返回排名最高的结果。
- 结果呈现:最后,搜索引擎将与查询最相关的文本结果呈现给用户。这可以是排名的文档列表,产品建议,问题答案等,具体取决于应用场景和需求。
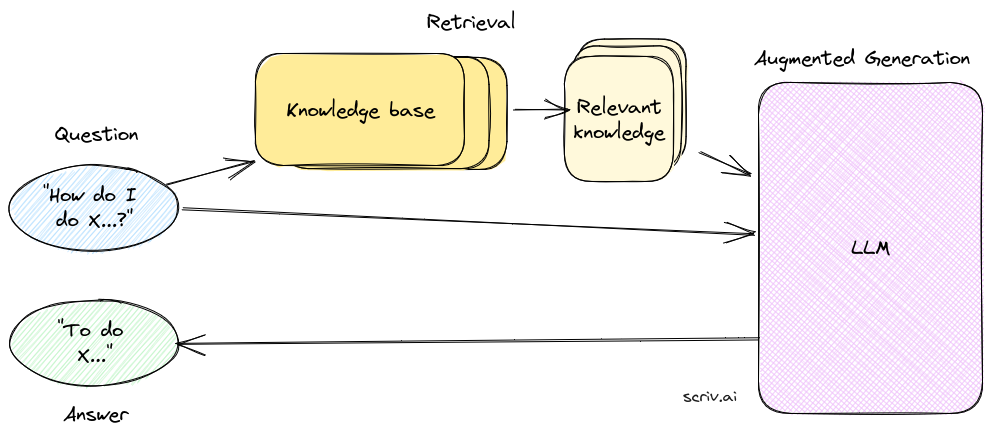
1.2 检索增强生成 (RAG)
检索增强生成(RAG)是Meta于2020年推出的一种技术,通过为模型提供相关上下文和问题/任务细节,提高了语言模型的性能;通过添加提供数据的信息检索来增强大型语言模型 (LLM) (如 ChatGPT)的功能。 RAG 意味着可以将自然语言处理限制为源自矢量化文档、图像、音频和视频 的企业内容 。
检索增强生成是机器学习领域两种强大技术的迷人融合:检索和生成。
- 检索:这是指系统搜索庞大的数据库或存储库以查找相关信息的过程。
- 生成:检索后,系统生成类似人类的文本,整合获取的数据。
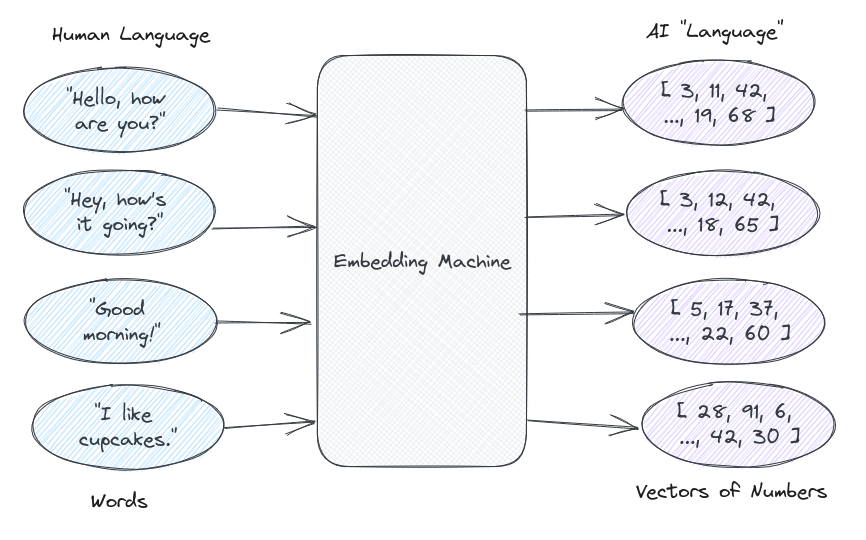
1.3 嵌入
嵌入(embeddings)捕捉文本、图像、视频或其他信息类型的“相关性”。这种相关性最常用于以下方面:
- 搜索:搜索词与文本主体的相似程度有多高?
- 推荐:两个产品有多相似?
- 分类:如何对文本进行分类?
- 聚类:如何识别趋势?
嵌入将离散信息(单词和符号)压缩成分布式连续值数据(向量)。

OpenAI 提供了一个 API(当然,还有其他模型也提供了类似的能力),可以使用其语言模型为文本字符串生成嵌入;最新的嵌入模型 text-embedding-ada-002 会输出 1536 个维度。
1.4 向量数据库
向量数据库是一种特殊类型的数据库,它可以存储和处理向量数据。它的一个关键特性是它能够快速地找到与给定向量最相似的其他向量,这是通过计算向量之间的距离(例如欧氏距离或余弦相似度)来实现的。
向量数据库 vs 关系型数据库 vs 非关系型数据库
向量数据库在处理大规模、高维度的任务时更为高效。由于向量数据库可以直接在向量空间中进行搜索,它们可以快速地找到与给定向量最相似的其他向量。向量数据库还可以处理非结构化的数据,如图像和文本,这是关系数据库无法做到的。
关系数据库是最常见的数据库类型,它们使用表格的形式来存储数据,并通过预定义的关系来连接不同的表。关系数据库的一个主要优点是它们可以保证数据的一致性和完整性。然而,关系数据库在处理大规模、高维度的数据时可能会遇到困难。
非关系数据库,也被称为NoSQL数据库,是一种灵活的数据库类型,它们可以处理各种类型的数据,包括结构化的、半结构化的和非结构化的数据。非关系数据库的一个主要优点是它们可以很好地处理大规模的数据,并且可以很容易地进行水平扩展。然而,非关系数据库在处理复杂的查询和高维度的数据时可能会遇到困难。
主流的向量数据库
在市场上,有几种流行的向量数据库,包括Faiss、Milvus、Annoy、Pinecone、chroma等。
| 特性/库 | Faiss | Milvus | Annoy | Pinecone | Chroma |
| 开发者 | Facebook AI | Zilliz (开源) | Spotify (开源) | Pinecone (SaaS) | Lystic Labs |
| 是否开源 | 是 | 是 | 是 | 否 | 是 |
| 云端支持 | 否 | 是 | 否 | 是 | 是 |
| 优点 | – 高性能的相似性搜索 – 丰富的索引选项 – 社区活跃度高 | – 强大的向量检索功能 – 支持多种索引算法- 社区支持佳 | – 轻量级,易于使用 – 内存效率高 – 支持大规模数据 | – 简单的托管服务 – 强大的实时搜索 – 可扩展性 | – 高性能向量搜索 – 容易使用的API – 自动索引优化 |
| 缺点 | – 需要自己搭建和管理 – 学习曲线较陡峭 | – 需要自己搭建和管理 – 配置相对复杂 | – 不适合大规模数据 – 仅提供基本功能 | – 价格相对较高 – 无法自托管 | – 有使用费用 – 某些功能可能有限制 |
| 价格 | 开源免费 | 开源免费 | 开源免费 | 按使用计费 | 免费试用可用 |
1.5 分词及token计算工具
下面提供了分词和token计算的工具,可以先上手体验一下
https://langchain-text-splitter.streamlit.app/
https://platform.openai.com/tokenizer
2 逻辑梳理
2.1 从流程的视角
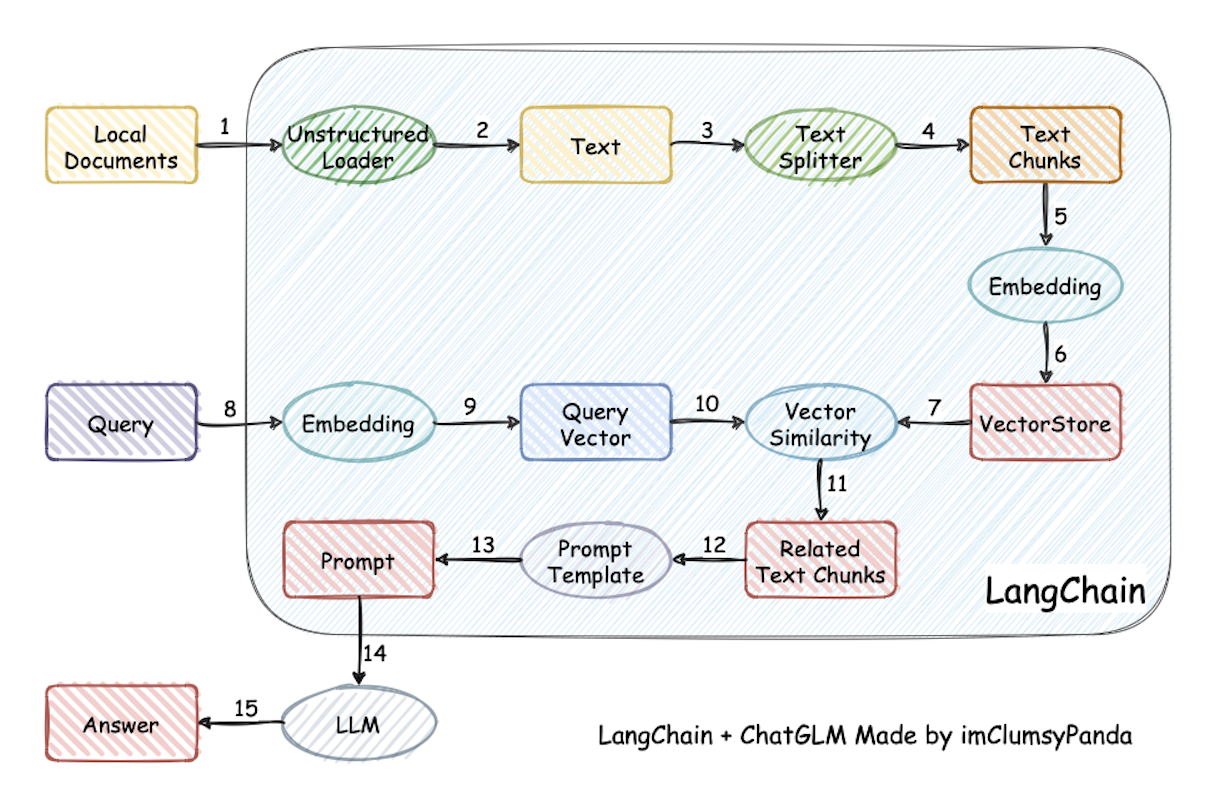
该图基于Langchain实现,图中内容基本上都是Langchain的六大模块中的小插件。该过程包括:加载文件 -> 读取文本 -> 文本分割 -> 文本向量化 -> 问句向量化 -> 在文本向量中匹配出与问句向量最相似的 top k个 -> 匹配出的文本作为上下文和问题一起添加到 prompt中 -> 提交给 LLM生成回答。
其中:
- 1-7步:向量数据库的生成部分,后期产品实现过程中其是异步的,可通过单独的逻辑来处理和实现。
- 8-11步:通过query向量后在向量数据库中的匹配搜索
- 12-15步:将搜索结果和query一并提交给LLM获取和组装答案
所以,1-11步是整个检索的过程,运用了向量数据库去寻找相似性内容的能力;12-15步是LLM进行内容创作的过程,让检索的答案进行组装并让输出更友好。这里面,如果使用传统的关键词匹配等搜索,只要在LLM的token不受限情况下,其实也可以完成后续的步骤。
2.2 从文档的视角
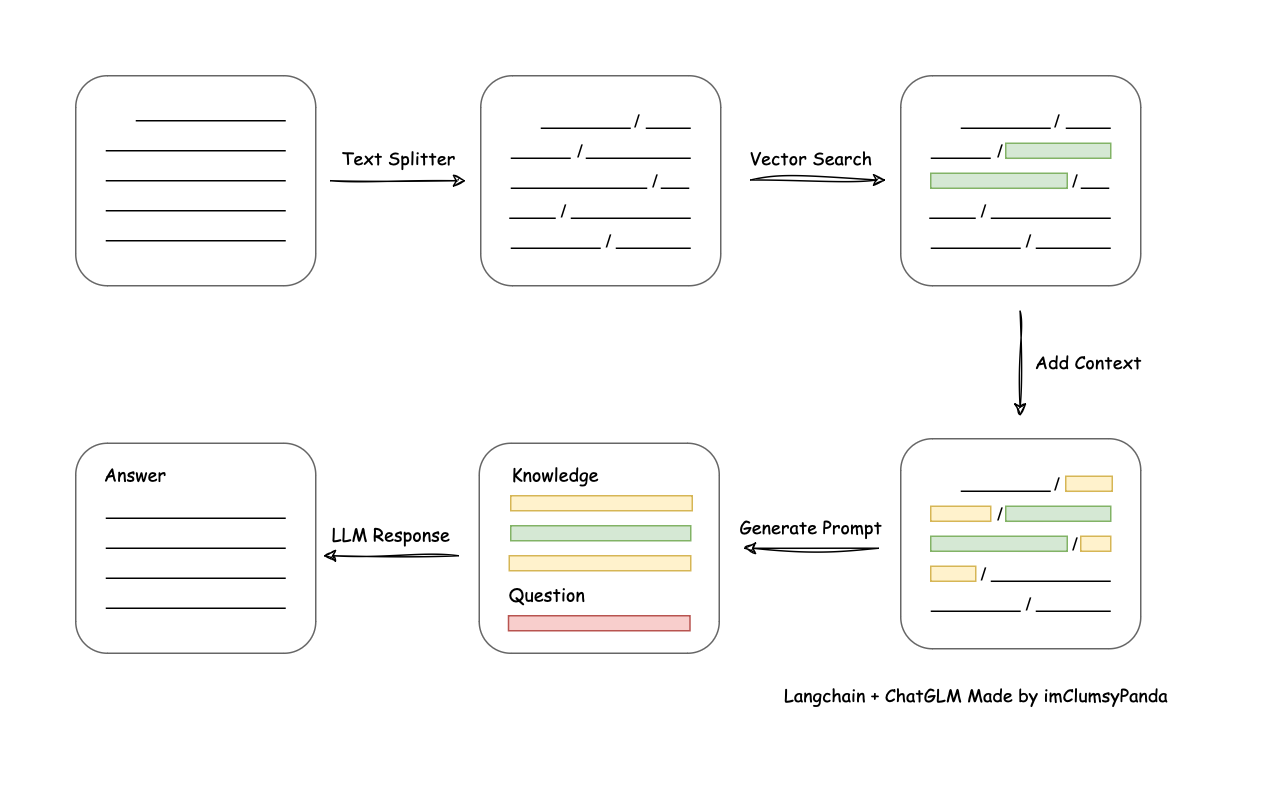
从文档的角度,分为以下五步:
- 文本读取和截取
- 根据不同源文件读取文件内容,如PDF/CSV/TXT等
- 进行文档的拆分截取,截取的规则在Langchain中提供了部分规则,但也可以进行自定义。比如为了更好的搜索效果,在中文中使用逗号等进行截取会更加合理。
- 文档向量化和基于向量的搜索
- 向量化:将拆分好的文本向量化,可以选择不同的LLM模型来执行(该步骤依然会消耗token)。在向量化和后续使用中需要关注向量维度等参数。所有向量化后的数据存入向量数据库。
- 向量数据库的搜索:通过向量化后的Query在向量数据库中进行搜索,选择
Top_K个结果。
- 文本回填
- 搜索结果的返回:将
Top_K个结果还原成真实文本信息 - 上下文的获取:在还原的文本信息适当的加入上下文内容;在该过程中会自动向前、先后截取部分的文本信息,同时如果有重叠还需要去重组合成一个大文本内容。
- 搜索结果的返回:将
- 生成提示词
参考信息:将3.b中的上下文回填信息作为参考资料素材Query提问:将Query作为提问素材- 模板组装:按照模板将参考信息和Query提问组装成一个Prompt
- LLM生成结果
3 潜在挑战
3.1 重复信息
原始文档中存在大量的重复内容,这些重复内容不太适合LLM,会产生很多不必要的上下文。
解决方案:
- 通过语义搜索过滤掉类似的文档。例如在将提示发送到ChatGPT之前,LangChain会检索20-30个相似文档,并通过向量检索技术过滤掉或者绕过重复文本,再将提示发送到ChatGPT。
- 利用最大边际相关算法来优化多样性。此搜索侧重于从其他检索到的向量中获取相以和多样的结果。
- 在存储之前对文档进行去重。但是,这种方法挑战性最大,因为需要大量时间和精力来确定一个相似性分数,用于判定文档是否重复。即便设置了一个相似性分数,它也未必十分准确,因为单个事物的单个向量维度差异巨大,分数稍有偏差,结果就会大相径庭。
3.2 冲突信息
如果对于同一个问题,不同来源的数据给出不同的回答,则会导致信息冲突。如果将这些数据据全部都给到LLM,可能会导致LLM混乱。
解决方案:
- 对来源进行优先级排序,并将优先级打分权重加入到检索中。
- 将所有源信息都传入生成步骤,交由LLM来判断哪个信息源更可靠。
3.3 时效性/文档的更新
文档可能一直处于变化中,后续会有不同的版本;LLM在具体使用中应该给予最新鲜的信息。
解决方案:
- 在检索中进行对最近的信息进行加权一一完全过滤过时的信息。
- 给生成信息带上时间戳一一要求LLM优先选择更近期的信息。
- 不断反思,即不断修订LLM对一个话题的理解。
3.4 元数据查询/语义查询与关键词查询的关联使用
某些情况下,用户提出的问题更侧重于元数据信息而非内容本身。
例如,用户可能会查询“1980年间关于外星人的电影”。其中,“关于外星人的电影”这一部分可以进行语义搜索,而”1980年间“其实是需要通过精确匹配来筛选结果的。
许多向量存储器都允许在查询前先通过元数据过滤器筛选数据。如果大家选择的向量存储器不支持在查询前进行元数据过滤,那么在语义搜索之后再过滤数据也是一个可行的方案。
解决方案:
- 元数据过滤器:通过精确匹配,先筛选出年份为1980年的电影。
- 语义搜索:查询筛选结果中”关于外星人“的电影。
3.5 多Query的多跳问题
用户可能会一次提出多个问题,这会给语义搜索带来挑战。
解决方案:
- 使用如LangChain之类的Al代理工具,将问题分解为几个步骤并使用语言模型作为推理引擎来检索所需信息。
- 集成GPTCache与LangChain,使用GPTCache存储LLM生成的问题和答案。在用户下一次提出类似查询时,GPTCache会先在缓存中搜索是否是已经问过的重复问题,之后如有必要再执行语义搜索并调用LLM。
4 【实现】开源系统 Langchain-Chatchat
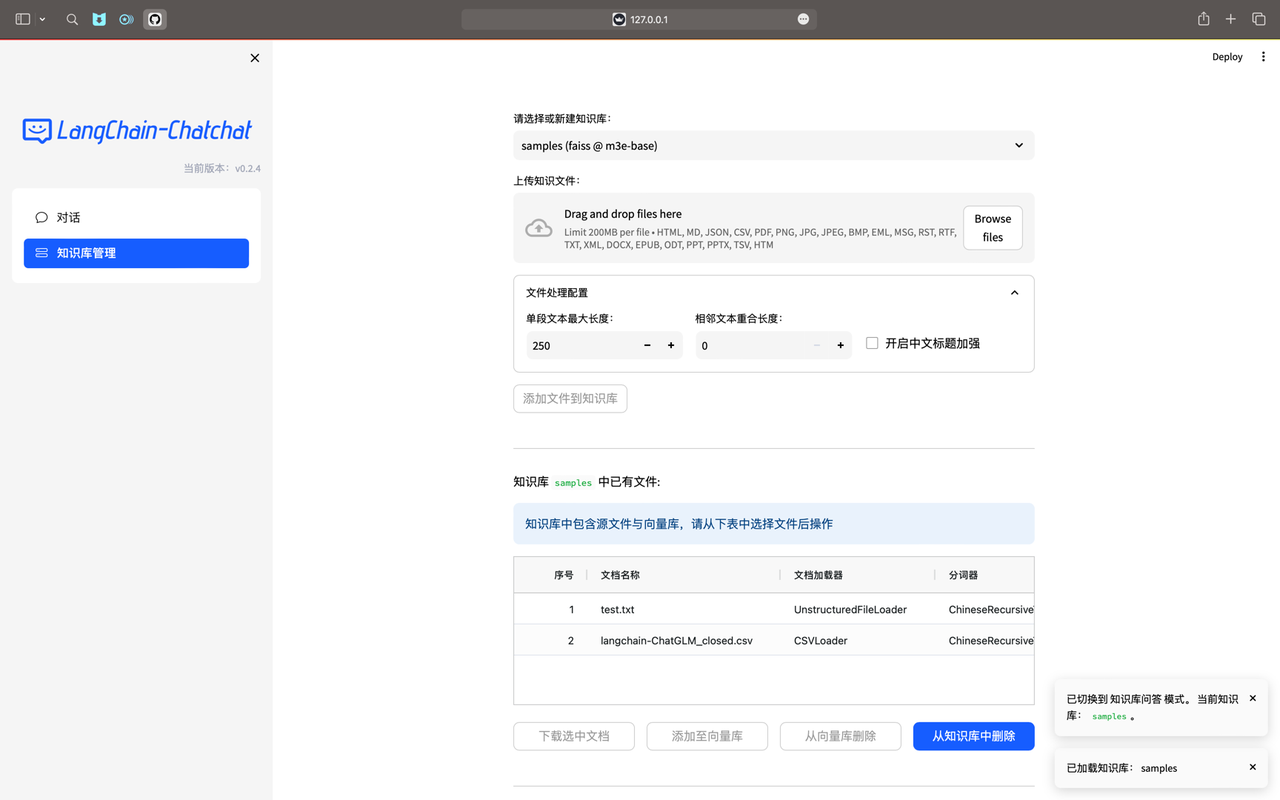
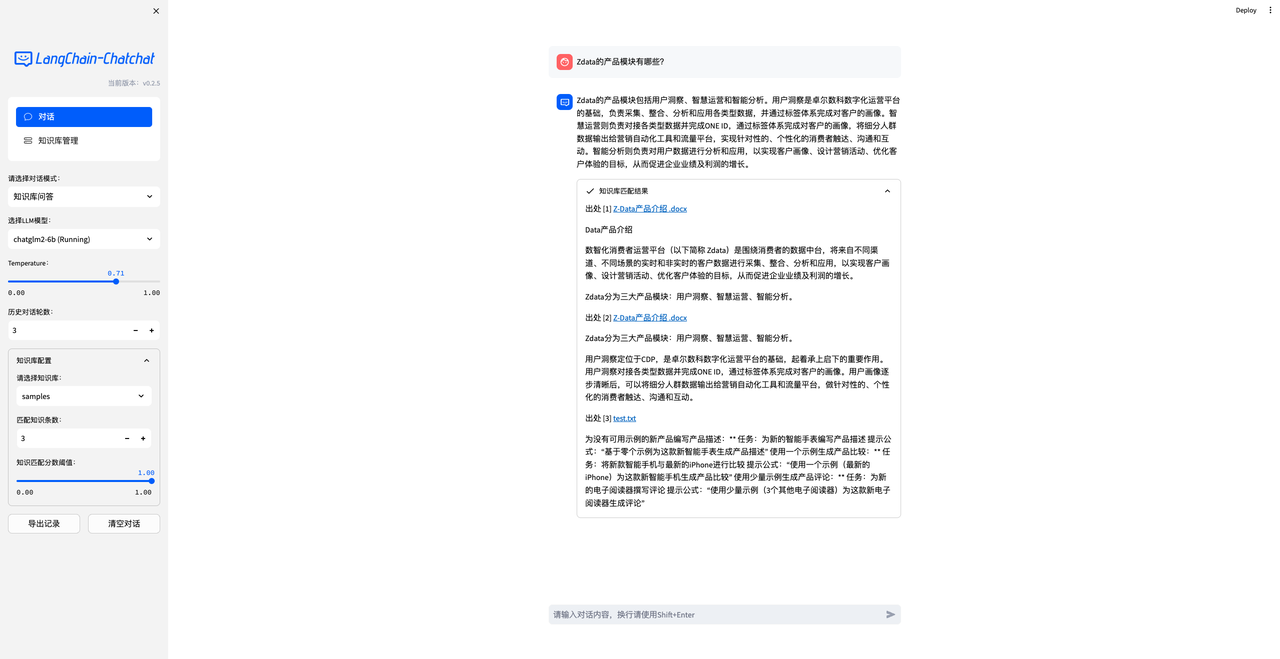
项目详见这里 https://github.com/chatchat-space/Langchain-Chatchat
参考资料
LangChain 联合创始人下场揭秘:如何用 LangChain 和向量数据库搞定语义搜索_Zilliz Planet的博客-CSDN博客
【译】私域聊天机器人如何工作?检索增强的内容生成(RAG)概述 · 语雀
【译】LangChain 父文档检索器:在大块和小块之间取得平衡 · 语雀
相关内容的传送门: