异常检测(Anomaly Detection),也被称为离群值检测(Outlier Detection)或异常值检测,是一种数据分析方法,用于识别数据集中的异常或不寻常的数据点,这些数据点与其他正常数据点不同。异常可以是意外事件、错误、故障或潜在的欺诈行为。异常检测在多个领域中都有应用,包括金融、网络安全、制造、医疗保健和环境监测等。
以下是异常检测的一些关键概念和方法:
- 异常类型:
- 异常可以分为不同类型,包括点异常(Point Anomaly)和上下文异常(Contextual Anomaly)。
- 点异常是指在数据集中的某个数据点是异常的,而上下文异常是指在特定上下文下的数据点异常。
- 基于阈值的方法:
- 最简单的异常检测方法是基于阈值的方法,其中异常被定义为与正常数据点的差异超过某个预定义阈值的数据点。
- 这种方法对于简单问题可能有效,但通常对于复杂数据集和多维数据不够稳健。
- 统计方法:
- 统计方法包括使用概率分布、均值、标准差等统计量来检测异常。
- 常见的统计方法包括Z分数、箱线图和百分位方法。
- 机器学习方法:
- 机器学习方法是异常检测中更强大和灵活的方法之一,它们可以处理复杂的数据和多维特征。
- 常见的机器学习方法包括基于密度的方法(如LOF和DBSCAN)、基于距离的方法(如k近邻)、聚类方法、以及基于深度学习的方法(如自编码器)。
- 时间序列异常检测:
- 对于时间序列数据,异常检测需要考虑时间维度。时间序列中的异常可以是突变、趋势变化或周期性异常。
- 常见的时间序列异常检测方法包括基于统计的方法、基于模型的方法和基于机器学习的方法。
- 特征工程:
- 在异常检测中,选择合适的特征对于检测性能至关重要。有时需要对数据进行预处理和特征工程,以提高异常检测的准确性。
- 评估和验证:
- 异常检测模型的性能通常使用指标如精确度、召回率、F1分数和ROC曲线下面积(AUC-ROC)等来评估。
- 交叉验证和分离数据集用于验证模型的泛化性能。
在实际应用中,异常检测通常需要结合领域知识来定义异常和设置阈值。不同的异常检测方法适用于不同的问题和数据类型,因此需要根据具体情况选择合适的方法。
问题的动机 Problem Motivation
异常检测(Anomaly detection)问题是机器学习算法的一个常见应用。这种算法的一个有趣之处在于:它虽然主要用于非监督学习问题,但从某些角度看,它又类似于一些监督学习问题。

举一个例子吧:假想你是一个飞机引擎制造商,当你生产的飞机引擎从生产线上流出时,你需要进行QA(质量控制测试),而作为这个测试的一部分,你测量了飞机引擎的一些特征变量,比如引擎运转时产生的热量,或者引擎的振动等等。
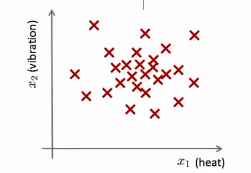
这样一来,你就有了一个数据集,如果你生产了m个引擎的话,将这些数据绘制成图表,看起来就是这个样子:

异常检测在许多领域中都非常重要,原因如下:
- 发现潜在问题:异常检测可以帮助发现数据中的潜在问题、错误或异常情况。这些问题可能导致系统故障、损失或安全风险。通过早期识别并解决这些问题,可以减少潜在的负面影响。
- 保障系统可靠性:在许多关键领域,如航空航天、医疗保健和金融,系统的可靠性至关重要。异常检测可以用于监测系统的运行状态,及时发现异常情况,从而确保系统的稳定性和安全性。
- 欺诈检测:在金融和电子商务领域,异常检测用于识别欺诈行为。这包括信用卡欺诈、网络欺诈、虚假账户等。通过检测异常交易或行为,可以防止经济损失并保护用户的利益。
- 质量控制:在制造业中,异常检测用于监测产品质量。通过检测生产过程中的异常情况,可以及时调整生产,降低次品率,并确保产品的质量。
- 故障检测:在工程和维护领域,异常检测用于监测设备和机器的状态。通过检测设备的异常情况,可以预防故障和损坏,降低维修成本。
- 网络安全:在网络安全领域,异常检测用于检测网络攻击和恶意行为。通过监测网络流量中的异常模式,可以及时识别潜在的威胁。
- 医疗诊断:在医疗领域,异常检测用于医学诊断和监测患者健康状况。通过监测生理数据中的异常模式,可以帮助医生提前发现疾病或患者的异常情况。
高斯分布 Gaussian Distribution
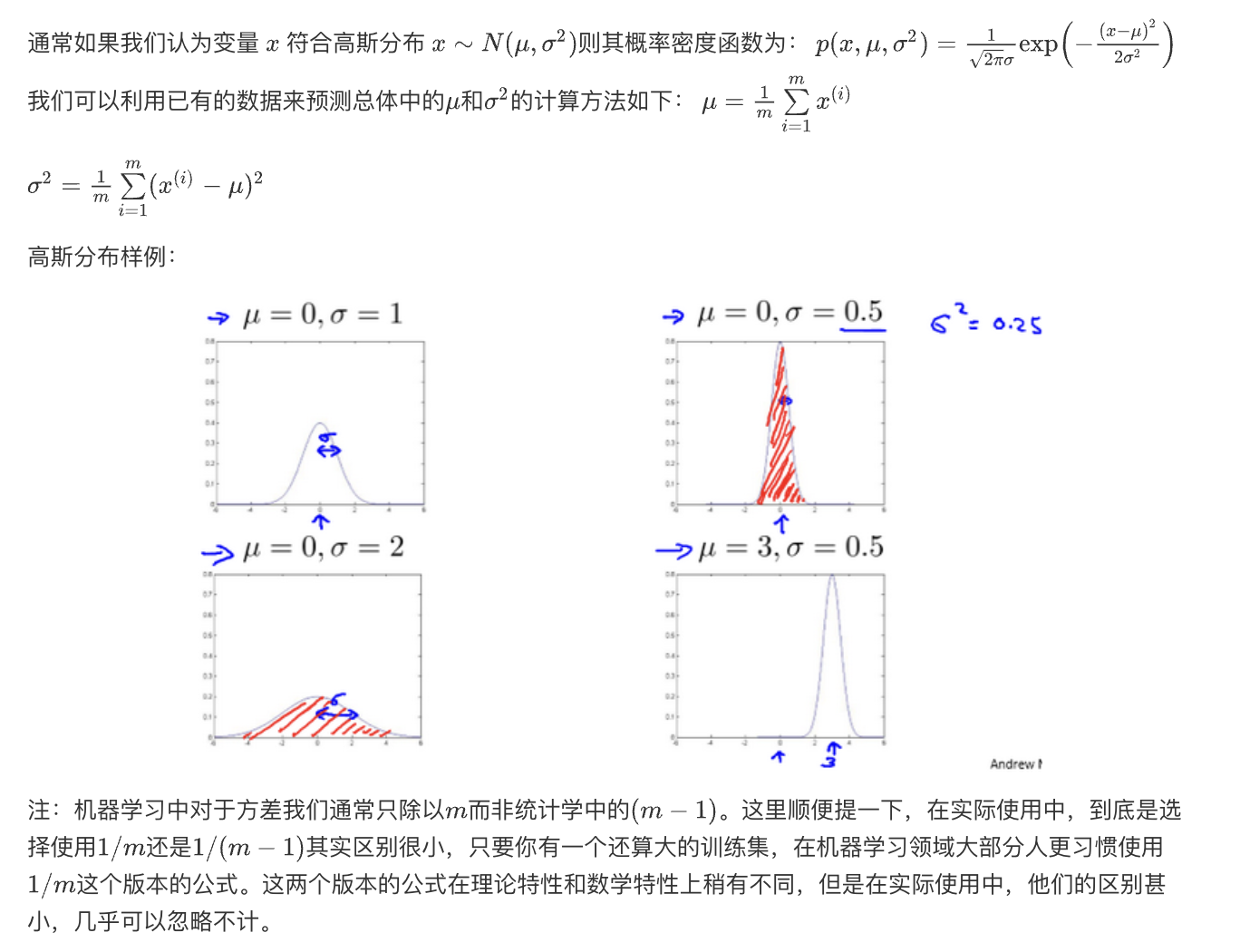
高斯分布,也称为正态分布(Normal Distribution),是统计学中最重要且最常见的概率分布之一。高斯分布通常用来描述自然界中的许多现象,例如测量误差、生物特征、金融数据等。它具有以下特点:
- 钟型曲线:高斯分布的概率密度函数呈现出典型的钟型曲线,其形状是对称的。曲线的中心对应于分布的均值,曲线的标准差控制曲线的宽度。
- 均值和标准差:高斯分布由两个参数完全描述,即均值(μ)和标准差(σ)。均值决定了分布的中心,标准差决定了分布的宽度或离散程度。标准差越大,分布越宽;标准差越小,分布越尖。
- 68-95-99.7法则:高斯分布具有一个重要的性质,即大约68%的数据点落在均值加减一个标准差的范围内,大约95%的数据点落在均值加减两个标准差的范围内,大约99.7%的数据点落在均值加减三个标准差的范围内。
- 正态性质:多个独立的随机变量的均值也符合高斯分布。这意味着在实际数据分析中,当涉及多个因素时,这些因素的均值往往符合高斯分布,这使得高斯分布成为许多统计方法的基础。
高斯分布在统计分析、假设检验、参数估计、机器学习等领域广泛应用,因为许多自然现象和数据都具有接近高斯分布的特性。在数据分析中,对数据是否满足高斯分布进行检验是常见的步骤之一,因为许多统计方法要求数据满足高斯分布的假设。如果数据不满足高斯分布,可能需要采用不同的统计方法或进行数据转换。
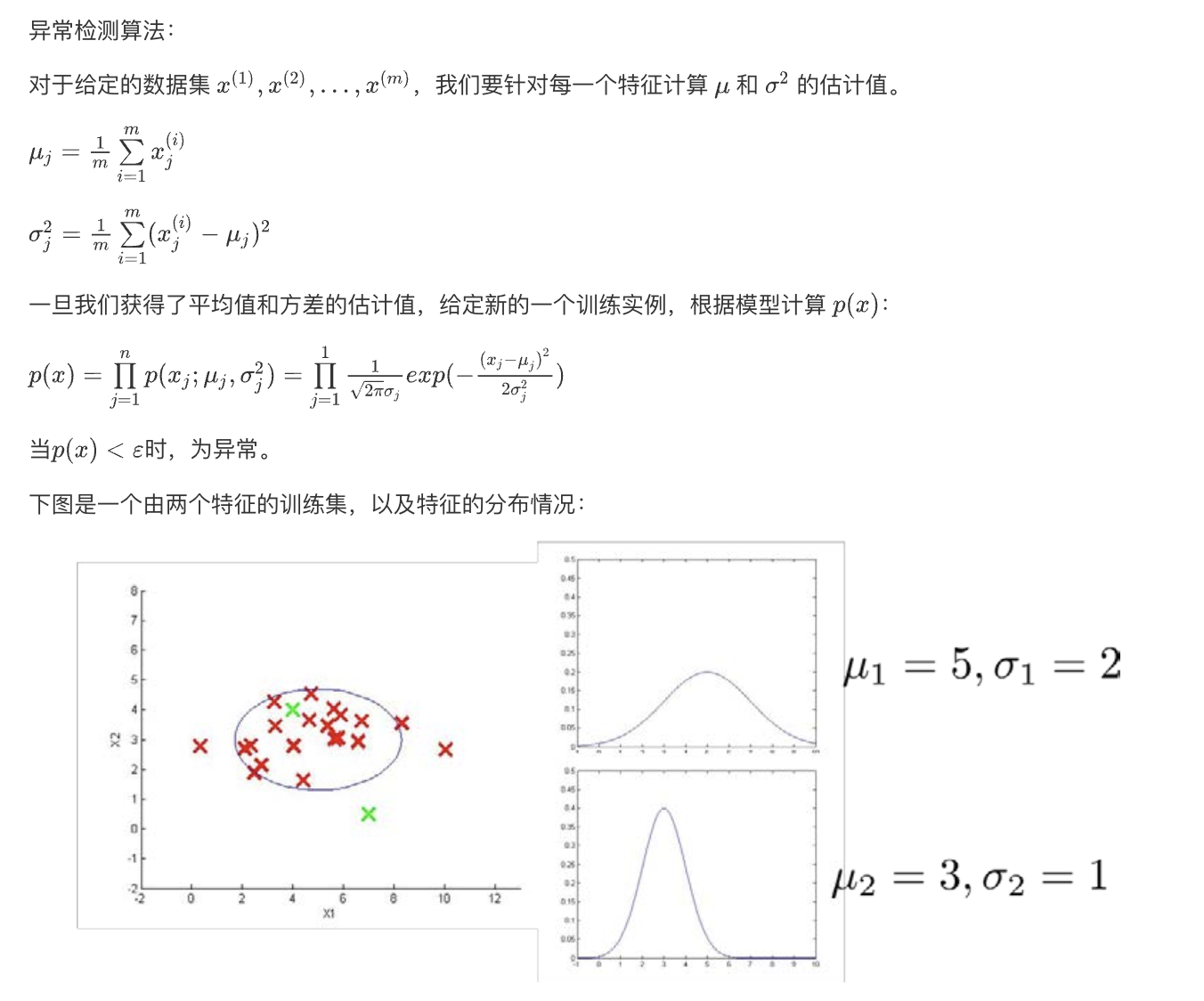
算法 Algorithm
高斯分布可以用于异常检测算法,通常称为高斯混合模型(Gaussian Mixture Model,GMM)或单变量高斯模型。这些模型使用高斯分布来建模正常数据的分布,然后通过检查新数据点与该分布的偏差来识别异常。
以下是使用高斯分布开发异常检测算法的一般步骤:
- 数据准备:
- 收集和准备数据集,确保数据集中包含足够的正常数据,以便建立正常数据的分布模型。
- 建立高斯模型:
- 对于单变量数据,可以使用单变量高斯分布模型。对于多变量数据,通常使用高斯混合模型(GMM)。
- 对于单变量高斯分布,计算数据的均值和标准差。
- 对于GMM,使用期望最大化(EM)算法估计多个高斯分布的参数,其中每个分布代表数据的一个簇。
- 计算概率密度:
- 对于每个数据点,计算它在模型中的概率密度。这可以通过高斯分布的概率密度函数计算。
- 对于GMM,计算每个分布的概率密度,然后将它们组合起来,以获得数据点的总概率密度。
- 设置阈值:
- 基于模型的概率密度,选择一个合适的阈值,通常是一个小概率值。如果数据点的概率密度低于阈值,将其标记为异常。
- 异常检测:
- 对于新的数据点,计算它们的概率密度,并与阈值进行比较。如果概率密度低于阈值,则将其标记为异常。
- 评估性能:
- 使用已知的异常数据集(如果可用),评估模型的性能。通常使用精确度、召回率、F1分数等指标来评估。
- 调整模型参数(可选):
- 根据性能评估结果,可以调整模型的参数,如阈值、高斯分布的数量等,以改善模型的性能。
需要注意的是,高斯模型在某些情况下对数据的分布假设可能不合适,尤其是在多模态、高度非线性或混合分布的情况下。在这种情况下,可能需要考虑使用其他异常检测方法,如基于密度的方法、基于聚类的方法或机器学习方法。选择适当的方法取决于数据的特点和异常检测的需求。
开发和评价一个异常检测系统 Developing and Evaluating an Anomaly Detection System
异常检测算法是一个非监督学习算法,意味着我们无法根据结果变量 y 的值来告诉我们数据是否真的是异常的。我们需要另一种方法来帮助检验算法是否有效。当我们开发一个异常检测系统时,我们从带标记(异常或正常)的数据着手,我们从其中选择一部分正常数据用于构建训练集,然后用剩下的正常数据和异常数据混合的数据构成交叉检验集和测试集。
例如:我们有10000台正常引擎的数据,有20台异常引擎的数据。 我们这样分配数据:
- 6000台正常引擎的数据作为训练集
- 2000台正常引擎和10台异常引擎的数据作为交叉检验集
- 2000台正常引擎和10台异常引擎的数据作为测试集
具体的评价方法如下:
- 根据测试集数据,我们估计特征的平均值和方差并构建p(x)函数
- 对交叉检验集,我们尝试使用不同的ε值作为阀值,并预测数据是否异常,根据F1值或者查准率与查全率的比例来选择 ε
- 选出 ε 后,针对测试集进行预测,计算异常检验系统的F1值,或者查准率与查全率之比
异常检测与监督学习对比 Anomaly Detection vs. Supervised Learning
构建的异常检测系统也使用了带标记的数据,与监督学习有些相似,下面是两者比较:
| 异常检测 | 监督学习 |
| 非常少量的正向类(异常数据y=1 ), 大量的负向类(y=0) | 同时有大量的正向类和负向类 |
| 许多不同种类的异常,非常难。根据非常 少量的正向类数据来训练算法。 | 有足够多的正向类实例,足够用于训练 算法,未来遇到的正向类实例可能与训练集中的非常近似。 |
| 未来遇到的异常可能与已掌握的异常、非常的不同。 | |
| 例如: 欺诈行为检测 生产(例如飞机引擎)检测数据中心的计算机运行状况 | 例如:邮件过滤器 天气预报 肿瘤分类 |
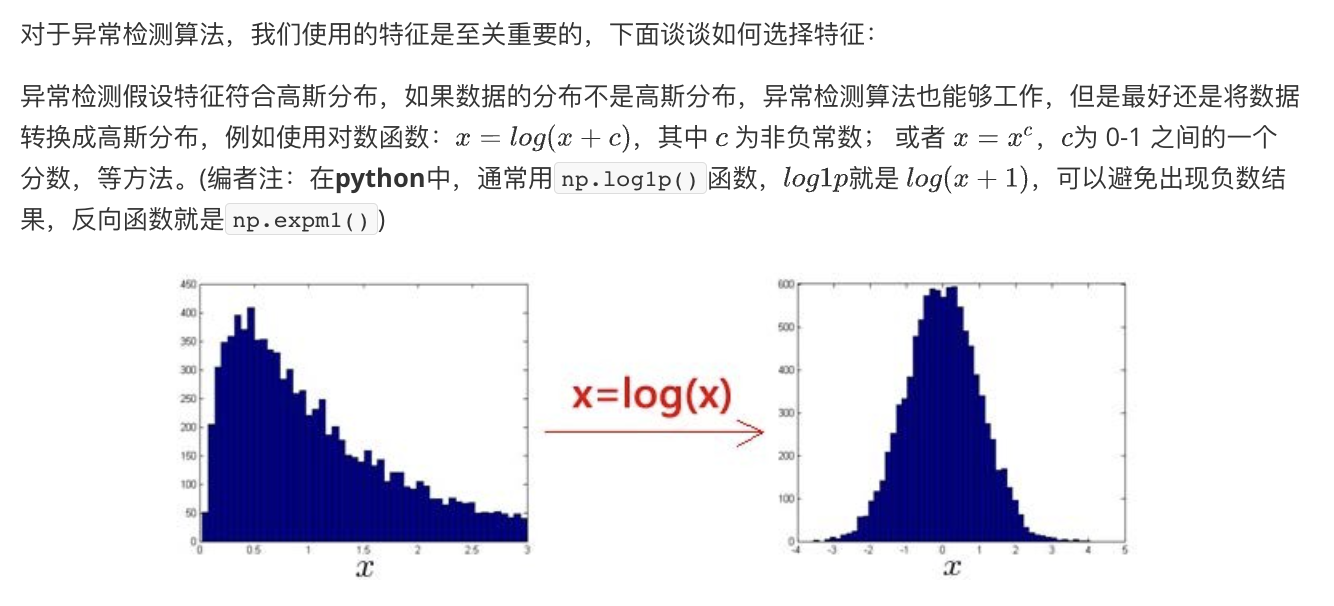
选择特征 Choosing What Features to Use