导语
AI不是人类替代品,而是人类能力增强工具。人机协作(Human-in-the-Loop, HITL)将人类认知的独特优势(判断力、创造力、细致理解)与AI的计算能力和效率战略性整合,确保AI在道德边界内运行、遵守安全协议并实现最佳效果。本文介绍HITL六大关键方面、两种变体、ADK实战示例与设计原则,适合需要构建安全可靠智能体系统的开发者。
TL;DR
- 核心:HITL将人类判断力与AI计算能力结合,包含人类监督、干预与纠正、学习反馈、决策增强、人机协作、上报策略六大方面。
- 价值:安全可靠(关键决策有人类把关)、伦理合规(确保符合人类价值观)、持续改进(人类反馈优化AI模型)、灵活适应(处理边界和模糊场景)。
- 变体:Human-in-the-Loop(人类在环内,参与每个关键决策点)和Human-on-the-Loop(人类在环上,定义总体策略,AI执行即时操作)。
- 实践:通过上报工具(escalate_to_human)实现HITL核心,工作流结构标准化处理流程,动态个性化注入客户上下文。
- 权衡:准确性↑ vs 可扩展性↓,人工监督→高准确+低吞吐量,完全自动→低准确+高吞吐量,混合方案→规模化用自动+关键点用HITL。
是什么:人机协作的核心定义
人机协同(Human-in-the-Loop, HITL):将人类认知的独特优势(判断力、创造力、细致理解)与AI的计算能力和效率战略性整合,确保AI在道德边界内运行、遵守安全协议并实现最佳效果。
核心理念:
AI ≠ 人类替代品
AI = 人类能力增强工具实现形式:
- 人类作为验证者/审查者 → 检查AI输出
- 人类主动引导 → 实时反馈和纠正
- 人机协作伙伴 → 共同解决问题
可视化示意图:
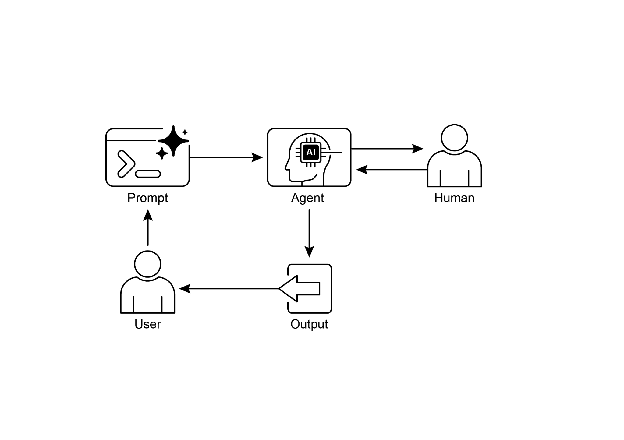
图1:人机协作设计模式 - 展示人类与AI协同工作的完整流程
读图要点:人类在关键决策点参与,AI处理常规任务,两者协同完成复杂工作。
常见误解澄清:
- ❌ HITL会降低自动化效率:会,但这是必要的权衡,关键是找到最优平衡点。
- ❌ 所有任务都需要人工干预:不需要,常规任务自动化,关键任务人工参与。
- ❌ HITL就是人工审核:HITL包含监督、干预、反馈、协作、上报等多个方面。
为什么:产生背景与适用场景
产生背景
AI局限性与HITL解决方案:
| 问题场景 | AI局限性 | HITL解决方案 |
|---|---|---|
| 高风险决策 | 错误后果严重(医疗/金融/法律) | 人类保留最终决策权 |
| 模糊与细微差别 | LLM难以可靠处理边界情况 | 人工审查复杂案例 |
| 伦理与道德推理 | AI缺乏价值观和常识推理 | 人类提供道德判断 |
| 创造性任务 | AI生成内容需优化 | 人类编辑确保质量 |
| 持续学习 | 模型需高质量训练数据 | 人工标注提供ground truth |
核心权衡:
准确性 ↑ vs 可扩展性 ↓
人工监督 → 高准确 + 低吞吐量
完全自动 → 低准确 + 高吞吐量
混合方案 → 规模化用自动 + 关键点用HITLHITL六大关键方面
| 方面 | 说明 | 实现方式 |
|---|---|---|
| 人类监督 (Human Oversight) | 监控AI性能和输出 | 日志审查、实时仪表板 |
| 干预与纠正 (Intervention) | AI遇错误或模糊场景时请求人工 | 纠正错误、提供缺失数据、指导方向 |
| 学习反馈 (Feedback for Learning) | 收集人类反馈优化模型 | RLHF(强化学习基于人类反馈) |
| 决策增强 (Decision Augmentation) | AI提供分析,人类做最终决定 | 辅助决策而非完全自主 |
| 人机协作 (Collaboration) | 发挥各自优势分工 | AI处理数据,人类处理创造性任务 |
| 上报策略 (Escalation Policies) | 明确何时上报给人类 | 超出能力范围时防止错误 |
怎么做:HITL的两种变体与ADK实战
HITL的两种变体
Human-in-the-Loop (人类在环内)
特点:人类参与每个关键决策点
适用:高频次人工干预场景
示例:每个可疑交易都需人工审核Human-on-the-Loop (人类在环上)
特点:人类定义总体策略,AI执行即时操作
适用:策略稳定,执行频繁的场景示例1:自动化金融交易
人类定义策略:
- 保持70%科技股 + 30%债券
- 单一公司不超过5%
- 跌破购买价10%自动卖出
AI执行:实时监控市场,满足条件立即交易示例2:智能呼叫中心
人类定义策略:
- 提到"服务中断"立即转技术支持
- 检测到高度沮丧立即转人工
AI执行:实时倾听,自动路由和上报ADK实战示例
核心代码结构
# 定义三个关键工具
def troubleshoot_issue(issue: str) -> dict:
"""故障排除工具"""
return {"status": "success", "report": f"Troubleshooting steps..."}
def create_ticket(issue_type: str, details: str) -> dict:
"""创建工单工具"""
return {"status": "success", "ticket_id": "TICKET123"}
def escalate_to_human(issue_type: str) -> dict:
"""上报人工工具 - HITL核心"""
return {"status": "success", "message": "Escalated to human specialist"}
# 配置技术支持智能体
technical_support_agent = Agent(
name="technical_support_specialist",
model="gemini-2.0-flash-exp",
instruction="""
你是技术支持专员:
1. 首先检查用户支持历史
2. 使用troubleshoot_issue分析问题
3. 指导用户完成基础排查
4. 问题持续则create_ticket记录
5. 复杂问题超出能力则escalate_to_human
保持专业且富有同理心的语气
""",
tools=[troubleshoot_issue, create_ticket, escalate_to_human]
)个性化回调函数
def personalization_callback(
callback_context: CallbackContext,
llm_request: LlmRequest
) -> Optional[LlmRequest]:
"""注入客户个性化信息"""
customer_info = callback_context.state.get("customer_info")
if customer_info:
personalization_note = f"""
IMPORTANT PERSONALIZATION:
Customer Name: {customer_info.get("name")}
Customer Tier: {customer_info.get("tier")}
Recent Purchases: {', '.join(customer_info.get("recent_purchases", []))}
"""
# 作为系统消息插入
system_content = types.Content(
role="system",
parts=[types.Part(text=personalization_note)]
)
llm_request.contents.insert(0, system_content)
return None # 继续使用修改后的请求关键设计要点
| 特性 | 作用 |
|---|---|
| 上报工具 | HITL核心,确保复杂案例转人工 |
| 工作流结构 | 标准化处理流程(排查→工单→上报) |
| 动态个性化 | 回调函数注入客户上下文 |
| 状态管理 | 跟踪用户历史和会话状态 |
对比与取舍:HITL的优势与局限
✅ 核心优势
| 优势 | 说明 |
|---|---|
| 安全可靠 | 关键决策有人类把关 |
| 伦理合规 | 确保符合人类价值观 |
| 持续改进 | 人类反馈优化AI模型 |
| 灵活适应 | 处理边界和模糊场景 |
| 质量保证 | 人类验证提高准确性 |
⚠️ 主要局限
| 局限 | 影响 | 缓解方案 |
|---|---|---|
| 可扩展性不足 | 人类无法处理海量任务 | 混合方案:自动化规模+HITL准确性 |
| 依赖专业知识 | 需要高技能领域专家 | 培训操作员,建立专家团队 |
| 成本高昂 | 人工成本 + 时间成本 | 优化上报阈值,自动化常规任务 |
| 隐私问题 | 敏感信息需匿名化 | 严格数据脱敏流程 |
| 响应延迟 | 人工干预增加时间 | 异步处理,优先级队列 |
常见错误与排错
典型坑位
| 问题 | 症状 | 识别方法 | 修复建议 |
|---|---|---|---|
| 上报阈值不当 | 过多或过少的人工干预 | 检查上报频率 | 优化上报阈值,平衡准确性和效率 |
| 人类成为瓶颈 | 响应时间过长 | 检查处理队列 | 异步处理,优先级队列,增加操作员 |
| 隐私泄露 | 敏感信息暴露 | 检查数据脱敏 | 严格数据脱敏流程,访问控制 |
| 反馈未利用 | 模型未改进 | 检查反馈循环 | 收集人类纠正数据,定期再训练模型 |
调试技巧
- 明确上报策略:定义清晰的上报条件,建立优先级机制。
- 优化人机分工:AI处理数据处理、模式识别,人类处理创造性、伦理判断。
- 设计反馈循环:收集人类纠正数据,定期再训练模型。
- 监控关键指标:上报频率、响应时间、用户满意度。
FAQ
Q1:如何确定哪些任务需要人工干预?
A:基于: 1) 错误后果严重程度;2) AI置信度阈值;3) 任务复杂度;4) 用户情绪状态;5) 合规要求。
Q2:HITL会降低自动化的效率吗?
A:会,但这是必要的权衡。关键是找到最优平衡点:常规任务自动化,关键任务人工参与。
Q3:如何防止人类成为瓶颈?
A:1) 异步处理;2) 优先级队列;3) 提高AI阈值减少上报;4) 增加操作员团队;5) 优化工具降低处理时间。
Q4:人工标注的质量如何保证?
A:1) 标注员培训;2) 多人交叉验证;3) 质量抽检;4) 建立标注指南;5) 反馈和纠正机制。
Q5:隐私问题如何处理?
A:1) 数据脱敏;2) 最小必要原则;3) 审计日志;4) 访问控制;5) 合规性审查。
Q6:Human-on-the-Loop与Human-in-the-Loop的选择?
A:
- In-the-Loop: 高频决策、低延迟要求、策略变化频繁
- On-the-Loop: 策略稳定、执行频繁、需要规模化
延伸阅读与引用
学术论文
- A Survey of Human-in-the-loop for Machine Learning
Xingjiao Wu等,2021
总结
人机协作(HITL)是将人类判断力与AI计算能力结合的核心模式。通过人类监督、干预与纠正、学习反馈、决策增强、人机协作、上报策略六大方面,HITL确保AI在道德边界内运行、遵守安全协议并实现最佳效果。虽然HITL会降低自动化效率,但这是必要的权衡,关键是找到最优平衡点:常规任务自动化,关键任务人工参与。