在openai DevDay上,openai提出了GPTs以及Assistants API等新概念新事物;加上一段时间的宫斗大戏,让GPTs的热度下降了不少。但很多业者还是在提及GPTs、Agent等概念,今天就来重点做下分析对比。
1 GPTs
OpenAI官方对GPTs的定义是,用户为特定目的创建的ChatGPT版本。任何人都可以创建 ChatGPT 的定制版本,以便在日常生活、特定任务、工作或家庭中更有帮助,然后与其他人分享该创作。
要构建一个GPTs也非常简单,不用代码,只需与GPT Builder(OpenAI推出的GPTs创建器)进行对话,并为其提供说明和其他知识,再选择GPTs能够执行的搜索网络、制作图像、分析数据等操作,一个GPTs就创建完成了。
OpenAI官方推出了16个GPTs,用户可以直接使用这些GPTs。
- DALL·E GPT:让你的想象变成图像。
- Data Analysis:放入任何文件,帮助分析和可视化您的数据。
- ChatGPT Classic:最新版本的GPT-4,没有附加功能。”
- Game Time:快速向任何年龄的玩家解释棋盘游戏或纸牌游戏。
- The Negotiator:帮助你为自己辩护并获得更好的结果,成为一名出色的谈判者。
- Creative Writing Coach:渴望阅读您的作品并为您提供反馈以提高您的技能。
- Cosmic Dream:有远见的数字奇迹画家。
- Tech Support Advisor:从设置打印机到对设备进行故障排除,逐步为您提供帮助。
- Coloring Book Hero:把任何想法变成异想天开的图画书页。
- Laundry Buddy:回答任何关于污渍、设置、分类和一切洗衣的事情。
- Sous Chef:根据你喜欢的食物和拥有的食材给你食谱。
- Sticker Whiz:把你最疯狂的梦想变成模切贴纸,直接送到你家门口。
- Math Mentor:帮助父母帮助他们的孩子学习数学。
- Hot Mods:把你的形象修改成真正狂野的东西。
- Mocktail Mixologist:用你手头的任何食材制作无酒精鸡尾酒食谱,让任何派对都大放异彩。
- genz 4 meme:?帮你理解行话和最新的表情包。
参考资料 Introducing GPTs | AI is about to completely change how you use computers | AI Agents 大爆发:软件 2.0 雏形初现,OpenAI 的下一步 - Foresight News
2 Agent
Openai提出的Agent四件套架构: LLM、记忆(Memory)、任务规划(Planning Skills)以及工具使用(Tool Use) 的集合,其中 LLM 是核心大脑,Memory、Planning Skills 以及 Tool Use 等则是 Agents 系统实现的三个关键组件。
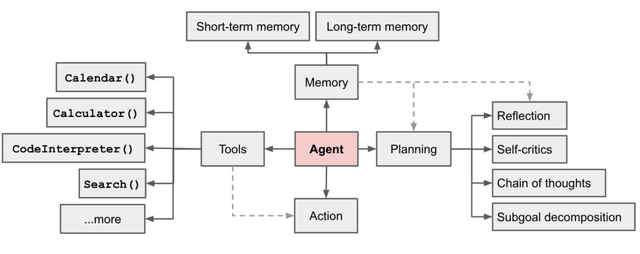
规划(Planning)
- 子目标和分解:AI Agents 能够将大型任务分解为较小的、可管理的子目标,以便高效的处理复杂任务;
- 反思和细化:Agents 可以对过去的行为进行自我批评和反省,从错误中吸取经验教训,并为接下来的行动进行分析、总结和提炼,这种反思和细化可以帮助 Agents 提高自身的智能和适应性,从而提高最终结果的质量。
记忆 (Memory)
- 短期记忆:所有上下文学习都是依赖模型的短期记忆能力进行的;
- 长期记忆:这种设计使得 AI Agents 能够长期保存和调用无限信息的能力,一般通过外部载体存储和快速检索来实现。
工具使用(Tool use)
AI Agents 可以学习如何调用外部 API,以获取模型权重中缺少的额外信息,这些信息通常在预训练后很难更改,包括当前信息、代码执行能力、对专有信息源的访问等。
2.1 规划
复杂任务的处理通常会涉及到多个步骤,因此 AI Agents 需要预先了解并对这些步骤进行规划。任务规划能力可以帮助 Agents 更好地理解任务结构和目标,以及在此基础上如何分配资源和优化决策,从而提高任务完成的效率和质量。
2.1.1 任务分解Task Decomposition
思维链(Chain of thought)
CoT 已经成为提升复杂任务模型性能的标准提示技术,它通过让模型「逐步思考」,利用更多的测试时间,将困难的任务拆解为更小、更简单的步骤。CoT 能够将大型任务转化为多个可管理的子任务,并揭示模型的思维链条,从而提高模型性能。这种技术使得模型更易于理解,也更容易获得更好的结果。
思维树( Tree of Thoughts)
思维树( ToT )则是通过在每一步探索多种推理可能性来扩展模型性能。ToT 首先将问题分解为多个思维步骤,每个步骤生成多个思维,从而创建一个树状结构。搜索过程可以是广度优先搜索(BFS)或深度优先搜索(DFS),每个状态由分类器(通过提示)或多数票进行评估。
LLM+P(Large Language Models + Planning)
利用外部经典规划师(External classical planner)进行长期规划。该方法利用规划域定义语言 (Planning Domain Definition Language,PDDL) 作为中间接口来描述规划问题。在这个过程中,LLM 需要完成以下几个步骤:
- 将问题转化为「问题 PDDL」;
- 请求经典规划师基于现有的「域 PDDL」生成 PDDL 计划;
- 将 PDDL 计划翻译回自然语言。
PDDL(Planning Domain Definition Language):
PDDL 是一种标准化和通用的规划领域语言,用于描述计划领域的形式语言。它能够用于描述可行动作、初始状态和目标状态的语言,用于帮助规划器生成计划。PDDL 通常被用于 AI 的自动规划问题,例如机器人路径规划、调度问题、资源分配等。
2.1.2 自我反思Self-Reflection
自我反思(Self-reflection)在任务规划中是一个重要环节,它让 Agents 能够通过改进过去的行动决策、纠正过往的错误以不断提高自身表现。在现实世界的任务中,试错(trial and error)是必不可少的,因而自我反思在其中扮演着至关重要的角色。
ReAct
通过将动作空间扩展为任务特定的离散动作和语言空间的组合,将推理和行动融合到 LLM 中。前者(任务特定的离散动作)使 LLM 能够与环境进行交互,例如使用维基百科搜索 API,而后者(语言空间)则促使 LLM 生成自然语言的推理轨迹。
Reflexion
一个为 AI Agents 提供动态记忆和自我反思能力,以提高推理能力的框架。该框架采用标准的强化学习设置,其中奖励模型提供简单的二元奖励(0/1),动作空间遵循 ReAct 中的设置,同时基于特定任务的行动空间,使用语言增强功能,以实现复杂的推理步骤。
Chain of Hindsight
核心思想是在上下文中呈现顺序改进输出的历史,并训练模型顺应趋势以产生更好的输出。该模型可以选择性地接收带有人类注释者的多轮指令,即人类提供的反馈注释,从而进一步提高模型的性能和准确性。
正则化项(Regularization Term)
正则化是机器学习中应对过拟合的一种简单而有效的技术。正则化项被添加到损失函数中来惩罚模型中过多的参数,以限制模型参数的数量和大小,使得参数值更加平滑。常见的正则化项包括 L1 正则化和 L2 正则化。
算法蒸馏(Algorithm Distillation)
Agents 能够与环境多次进行交互,并不断进步,AD 连接这种学习历史记录并将其馈送到模型中。AD 算法在上下文强化学习方面具有很好的性能,并且比其他基线更快地学习和改进。
2.2 记忆
2.2.1 Memory 的类型
Memory 可以定义为用于获取、存储、保留和稍后检索信息的进程。人类的大脑记忆可以分为以下几类:

• 感觉记忆(Sensory memory)作为原始输入的学习嵌入表示,包括文本、图像或其他模式;
• 短期记忆(Short-term memory)作为上下文学习,但由于 Transformer 有限上下文窗口长度的限制,这种记忆短暂且有限;
• 长期内存(Long-term memory)作为 AI Agents 可以在查询时处理的外部向量存储,可通过快速检索访问。
感觉记忆(Sensory Memory)
记忆的最早阶段,提供在原始刺激结束后保留感官信息(视觉,听觉等)印象的能力。通常,感觉记忆只能持续几秒钟。子类别包括标志性记忆(视觉)、回声记忆(听觉)和触觉记忆(触摸)。
短期记忆 / 工作记忆(Short-Term Memory, STM/ Working Memory)
存储了我们目前知道并执行复杂的认知任务(如学习和推理)所需的信息。短期记忆被认为具有大约 7 个项目的容量,持续 20-30 秒。
长期记忆(Long-Term Memory ,LTM)
长期记忆可以在很长一段时间内保存信息,从几天到几十年不等,存储容量基本上是无限的。LTM 又可以被分为:
• 显式 / 陈述性记忆(Explicit / declarative memory):这是对事实和事件的记忆,是指那些可以有意识地回忆起来的记忆,包括情景记忆(事件和经历)和语义记忆(事实和概念);
• 内隐 / 程序记忆(Implicit / Procedural memory): 这种类型的记忆是无意识的,涉及自动执行的技能和例程,例如骑自行车或在键盘上打字。
2.2.2 最大内积搜索(MIPS)
外部存储器可以减少有限注意力(Finite Attention Span)的限制。一种标准做法是将信息的 embedding 保存到向量存储数据库中,该数据库支持快速最大内积搜索(Maximum Inner Product Search,MIPS)。为了提高检索速度,常见的方法是使用近似最近邻(ANN)算法,以返回大约前 k 个最近邻,以牺牲一定的精度损失来换取巨大的加速,这种方法可以减轻模型处理大量历史信息时的计算负担,提高模型的效率和性能。
最大内积搜索(Max-Inner Product Search) 算法用于在高维向量空间中搜索最相似的向量,它的基本思想是,给定一个查询向量 q 和一个向量集合 S,目标找到 S 中与 q 的内积最大的向量。最大内积搜索算法在实际问题中有很广泛的应用,特别是在信息检索、推荐系统、语义搜索等需要处理高维向量数据的领域。
2.3 工具
给 LLM 配备外部工具可以显著扩展大模型的功能,使其能够处理更加复杂的任务。
2.3.1 MRKL 架构
MRKL(Modular Reasoning, Knowledge and Language)即「模块化推理、知识和语言」,是一种用于自主代理 的神经符号架构。MRKL 架构的设计中包含了「专家(expert)」模块的集合,通用 LLM 将扮演路由器(router)的角色,通过查询路由找到最合适的专家模块。这些模块可以是神经模块(Neural),例如深度学习模型,也可以是符号模块,例如数学计算器、货币转换器、天气 API 等。
MRKL 的核心思想是,现有 LLM(如 GPT-3 )等仍存在一些缺陷,包括遗忘、外部知识的利用效率低下等。为此,MRKL 将神经网络模型、外部知识库和符号专家系统相结合,提升了自然语言处理的效率和精度。通过 MRKL 系统,不同类型的模块能够被整合在一起,实现更高效、灵活和可扩展的 AI 系统。
2.3.2 让模型学习使用外部工具的 API
TALM(工具增强语言模型 Tool Augmented Language Models)和 Toolformer 都是通过微调 LM 来学习使用外部工具 API。为了提高模型的性能和准确性,数据集根据新添加的 API 调用注释是否可以提高模型输出的质量进行了扩展。
2.3.3 HuggingGPT
HuggingGPT 将 ChatGPT 作为任务计划器,可以根据模型描述,选择 HuggingFace 平台中可用的模型,并根据执行结果总结响应。
2.3.4 API-Bank
API-Bank 是用于评估工具增强 LLM 性能的基准,它包含了 53 个常用的 API 工具、一个完整的工具增强型 LLM 工作流程,涉及到 568 个 API 调用的 264 个带注释的对话。