导语
没有记忆的智能体每次对话都是全新的开始,无法维持连贯性,也无法个性化响应。记忆管理通过短期记忆(上下文窗口)和长期记忆(向量数据库)两种机制,让智能体记住历史交互、用户偏好和学习经验,实现对话连贯性、个性化响应并持续改进。本文介绍 Google ADK 和 LangChain 的记忆管理架构、State 设计最佳实践与实战案例,适合需要构建持久化智能体的开发者。
TL;DR
- 核心:记忆管理分为短期记忆(上下文窗口/Session State)和长期记忆(向量数据库/外部存储),使智能体维持对话连贯性、个性化响应并持续改进。
- 价值:短期记忆维持对话流畅性,长期记忆实现跨会话连续性、个性化和学习能力。
- 架构:Google ADK 使用 Session(会话)、State(状态)、Memory(长期记忆)三要素;LangChain 使用 ChatMessageHistory、ConversationBufferMemory、InMemoryStore。
- 实践:State 使用前缀机制(user:/app:/temp:),通过 append_event 更新,禁止直接修改;Memory 使用语义搜索检索相关信息。
- 边界:上下文窗口越长越好是误解,应该用长期记忆存储重要信息;State 是临时便签,Memory 是永久档案。
是什么:记忆管理的核心定义
记忆管理(Memory Management):智能体保留并利用过往交互、观察和学习经验中的信息的能力,分为短期记忆(即时上下文)和长期记忆(持久化知识库)两种类型,使智能体能维持对话连贯性、个性化响应并持续改进。
记忆类比:
人类记忆 智能体记忆
────────── ──────────────
工作记忆 → 短期记忆(Context Window / Session State)
长期记忆 → 长期记忆(Vector DB / External Storage)可视化示意图:
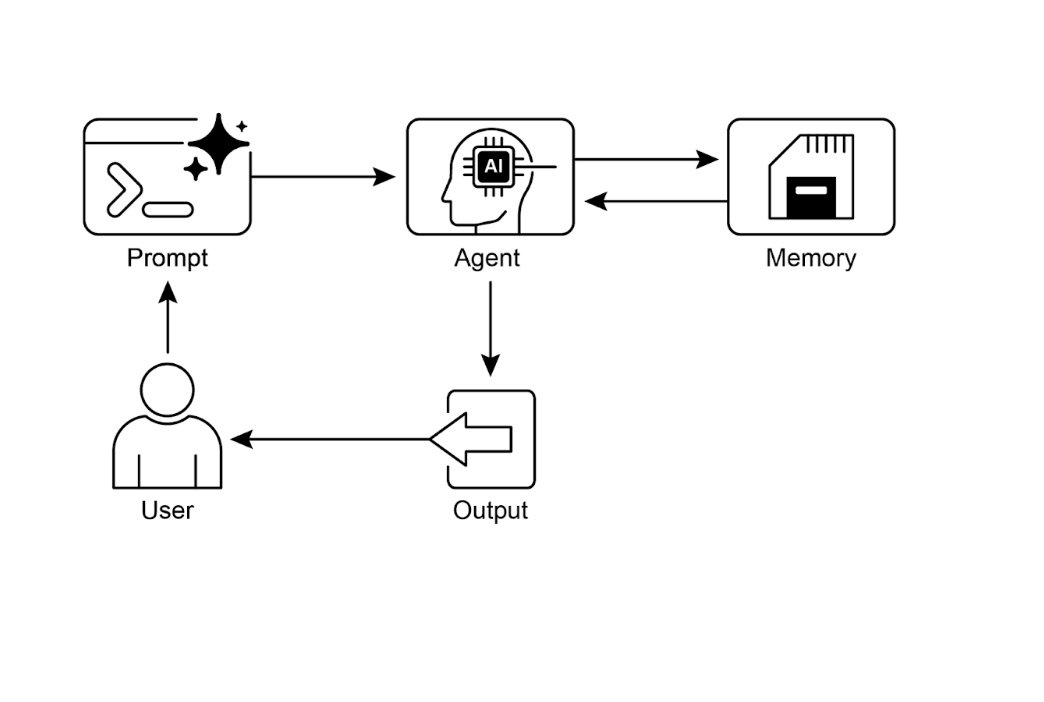
图1:记忆管理设计模式 - 从短期记忆到长期记忆的完整架构
读图要点:短期记忆用于当前对话,长期记忆用于跨会话知识存储和检索。
常见误解澄清:
- ❌ 上下文窗口越长越好:长上下文增加成本和延迟,且仍是短期记忆(会话结束丢失),应该用长期记忆存储重要信息。
- ❌ State 和 Memory 可以混用:State 是临时便签,Memory 是永久档案,职责不同。
- ❌ 可以直接修改 session.state:应该通过 append_event 更新,直接修改不持久化。
为什么:产生背景与适用场景
产生背景
无记忆的问题:
- 无法维持对话连贯性:每次对话都是全新开始,无法理解上下文。
- 无法个性化响应:无法记住用户偏好和历史行为。
- 无法持续学习:无法从过往经验中改进。
记忆管理的优势:
- ✅ 维持对话流畅性
- ✅ 实现跨会话连续性
- ✅ 个性化响应
- ✅ 持续改进和学习
短期记忆 vs 长期记忆
| 维度 | 短期记忆 (Short-Term) | 长期记忆 (Long-Term) |
|---|---|---|
| 存储位置 | 上下文窗口 / Session State | 外部数据库 / 向量数据库 |
| 作用域 | 当前对话 | 跨多个会话 |
| 生命周期 | 会话结束后丢失 | 持久化存储 |
| 容量 | 受LLM上下文窗口限制 | 理论上无限 |
| 访问方式 | 直接读取 | 查询检索(语义搜索) |
| 内容 | 最近消息、工具调用结果、反思 | 用户偏好、历史交互、知识库 |
| 类比 | 工作台/草稿本 | 档案室/图书馆 |
为什么需要两种记忆?
- 短期记忆:维持对话流畅性,处理当前上下文
- 长期记忆:实现跨会话连续性,个性化和学习能力
怎么做:Google ADK 与 LangChain 实现
Google ADK 记忆管理架构
核心三要素
| 组件 | 作用 | 生命周期 | 类比 |
|---|---|---|---|
| Session | 独立聊天线程,记录消息和动作 | 单次对话 | 会议记录本 |
| State | 会话内的临时数据(键值对) | 单次对话 | 便签纸 |
| Memory | 可搜索的长期知识库 | 跨多个会话 | 档案室 |
1. Session(会话)
定义:一个独立的对话线程
包含内容:
- 唯一标识符(id, app_name, user_id)
- 事件历史(Event对象)
- 会话状态(state)
- 更新时间戳(last_update_time)
SessionService 实现方式:
| 类型 | 适用场景 | 持久化 |
|---|---|---|
| <code>InMemorySessionService</code> | 测试/开发 | ❌ 重启丢失 |
| <code>DatabaseSessionService</code> | 生产环境 | ✅ 数据库持久化 |
| <code>VertexAiSessionService</code> | GCP生产 | ✅ Vertex AI托管 |
2. State(状态)
定义:会话的临时工作记忆,以字典形式存储数据
State 前缀机制:
| 前缀 | 作用域 | 生命周期 | 示例 |
|---|---|---|---|
| (无前缀) | 当前会话 | 会话结束销毁 | <code>task_status</code> |
| <code>user:</code> | 用户级,跨所有会话 | 持久化(取决于Service) | <code>user:login_count</code> |
| <code>app:</code> | 应用级,所有用户共享 | 持久化 | <code>app:feature_flags</code> |
| <code>temp:</code> | 当前处理轮次 | 单次处理后销毁 | <code>temp:validation_needed</code> |
State 更新方式:
方法1:简单方式 - output_key
greeting_agent = LlmAgent(
name="Greeter",
model="gemini-2.0-flash",
output_key="last_greeting" # 自动保存响应到state
)方法2:标准方式 - EventActions.state_delta
def log_user_login(tool_context: ToolContext) -> dict:
state = tool_context.state
state["user:login_count"] = state.get("user:login_count", 0) + 1
state["task_status"] = "active"
return {"status": "success"}❌ 禁止直接修改:
# 错误示例 - 不要这样做!
session.state["key"] = "value" # 绕过事件机制,不持久化3. Memory(长期记忆)
MemoryService 实现:
| 类型 | 存储方式 | 适用场景 |
|---|---|---|
| <code>InMemoryMemoryService</code> | 内存 | 测试 |
| <code>VertexAiRagMemoryService</code> | Vertex AI RAG | 生产,语义搜索 |
核心操作:
- <code>add_session_to_memory()</code>: 从会话提取信息存储
- <code>search_memory()</code>: 语义搜索相关信息
LangChain / LangGraph 记忆管理
LangChain 短期记忆
1. ChatMessageHistory - 手动管理
from langchain.memory import ChatMessageHistory
history = ChatMessageHistory()
history.add_user_message("我下周要去纽约。")
history.add_ai_message("太好了!这是一个很棒的城市。")
print(history.messages)2. ConversationBufferMemory - 自动集成
from langchain.memory import ConversationBufferMemory
memory = ConversationBufferMemory(
memory_key="history", # 提示词中的变量名
return_messages=True # 返回消息对象列表(推荐)
)
# 集成到链中
conversation = LLMChain(llm=llm, prompt=prompt, memory=memory)LangGraph 长期记忆
三种类型(类比人类记忆):
| 类型 | 定义 | 实现方式 | 用途 |
|---|---|---|---|
| 语义记忆 | 事实和概念 | 用户档案(JSON) | 存储偏好、领域知识 |
| 情景记忆 | 过往经历 | 少样本示例 | 学习如何完成任务 |
| 程序记忆 | 如何执行任务 | System Prompt | 核心指令,反思更新 |
InMemoryStore 示例:
from langgraph.store.memory import InMemoryStore
store = InMemoryStore(index={"embed": embed, "dims": 2})
namespace = ("user_123", "chitchat")
# 存储
store.put(namespace, "memory_key", {"rules": ["用户喜欢简短语言"]})
# 获取
item = store.get(namespace, "memory_key")
# 搜索
items = store.search(namespace, query="语言偏好")对比与取舍:State 设计最佳实践
State 设计最佳实践
✅ 应该做的:
- 保持简洁,使用基本数据类型
- 键名清晰,正确使用前缀
- 通过<code>append_event</code>更新状态
- 避免深度嵌套
❌ 不应该做的:
- 直接修改<code>session.state</code>字典
- 存储大量数据在State(用Memory)
- 混淆State和Memory的职责
Vertex Memory Bank
定义:Vertex AI Agent Engine 的托管长期记忆服务
核心能力:
- 使用Gemini模型异步分析对话历史
- 自动提取关键事实和用户偏好
- 按用户ID组织,智能更新和解决矛盾
- 支持完整召回或语义搜索
使用示例:
from google.adk.memory import VertexAiMemoryBankService
memory_service = VertexAiMemoryBankService(
project="PROJECT_ID",
location="LOCATION",
agent_engine_id=agent_engine_id
)
# 自动存储会话记忆
await memory_service.add_session_to_memory(session)跨框架支持:
- Google ADK (原生集成)
- LangGraph (API调用)
- CrewAI (API调用)
常见错误与排错
典型坑位
| 问题 | 症状 | 识别方法 | 修复建议 |
|---|---|---|---|
| State数据丢失 | 会话结束后数据消失 | 检查是否使用持久化SessionService | 使用DatabaseSessionService或VertexAiSessionService |
| 直接修改State | 数据不持久化 | 检查是否使用append_event | 通过append_event更新状态 |
| State和Memory混淆 | 重要信息存储在State | 检查数据生命周期需求 | 重要信息应存入Memory |
| 上下文窗口溢出 | 超出Token限制 | 检查上下文长度 | 使用长期记忆存储历史 |
调试技巧
- 检查SessionService类型:确认是否使用持久化服务。
- 验证State前缀:确保正确使用user:/app:/temp:前缀。
- 测试Memory检索:验证语义搜索是否正常工作。
- 监控上下文长度:避免超出模型限制。
FAQ
Q1:上下文窗口越长越好吗?
A:不一定。长上下文增加成本和延迟,且仍是短期记忆(会话结束丢失)。应该用长期记忆存储重要信息。
Q2:如何选择SessionService?
A:
- 测试/开发:<code>InMemorySessionService</code>
- 生产(自建):<code>DatabaseSessionService</code>
- 生产(GCP):<code>VertexAiSessionService</code>
Q3:State和Memory的区别?
A:State是临时便签,Memory是永久档案。State用于当前会话数据,Memory用于跨会话知识。
Q4:如何避免State数据丢失?
A:1) 使用持久化的SessionService;2) 通过<code>append_event</code>更新;3) 重要信息应存入Memory而非State。
Q5:向量数据库如何实现语义搜索?
A:将信息转为向量,存储在向量数据库。检索时,将查询转为向量,计算相似度,返回最相关结果。
Q6:三种长期记忆类型如何选择?
A:
- 语义记忆:事实和偏好 → 用户档案
- 情景记忆:如何做任务 → 少样本示例
- 程序记忆:核心指令 → System Prompt + 反思更新
延伸阅读与引用
官方文档
总结
记忆管理是智能体实现连贯对话、个性化响应和持续学习的核心能力。通过短期记忆(Session/State)和长期记忆(Memory)的分层架构,智能体可以维持对话流畅性,同时实现跨会话的连续性和个性化。Google ADK 的三要素架构(Session、State、Memory)和 LangChain 的多种记忆类型为不同场景提供了灵活的选择。