导语
智能体通常依赖预定义知识,难以应对新情境或开放式问题。在复杂动态环境中,静态信息不足以实现真正创新或发现。关键挑战是让智能体超越简单优化,主动寻找新信息和“未知的未知”,实现从被动反应到主动探索的范式转变,扩展系统认知和能力。
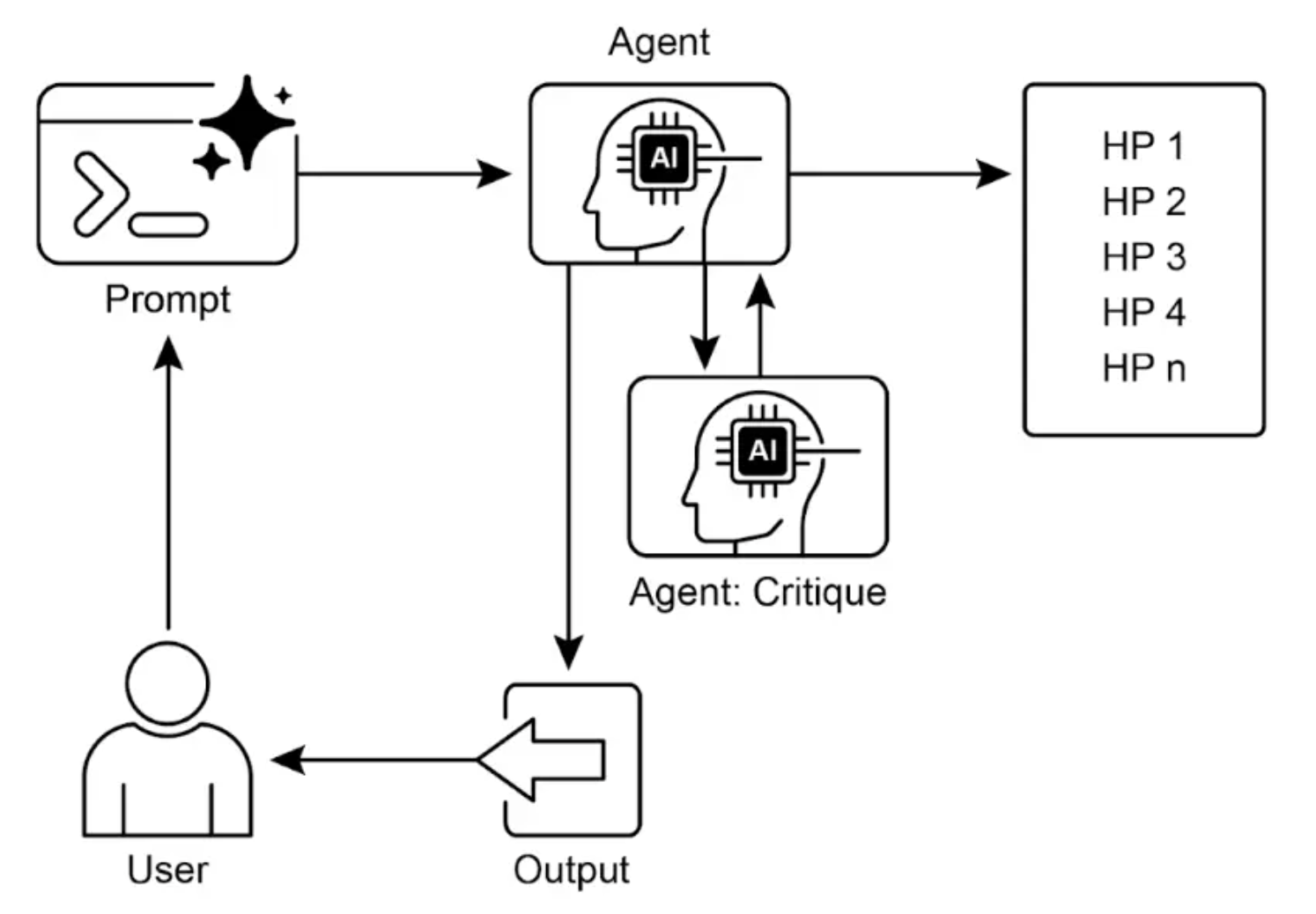
标准做法是构建专为自主探索与发现设计的智能体 AI 系统,通常采用多智能体框架,专用 LLM 协作模拟科学方法。不同智能体负责假设生成、评审和进化,结构化协作使系统能智能导航信息空间、设计实验并生成新知识。自动化探索环节,增强人类智力,加速发现进程。
传统优化只在已知空间内寻找最优解,无法处理“未知之未知”。探索与发现模式让智能体主动进入未知领域,生成新知识,通过多智能体协作和迭代推理推动真正的创新。本文介绍探索与发现的关键场景、Google Co-Scientist 多智能体架构、Agent Laboratory 框架与探索-利用平衡策略,适合需要构建创新型智能体系统的开发者与研究者。
<img src="https://ymmcheer-1257617206.cos.ap-nanjing.myqcloud.com/typora/image-20251125215445827.png" alt="image-20251125215445827" style="zoom:33%;" />
{kind=link}
TL;DR
- 核心:智能体主动寻找新信息、发现新可能性、识别未知之未知,而非仅在预定义空间内优化。
- 场景:科学研究自动化、策略游戏、市场趋势发现、安全漏洞挖掘、创意生成、个性化教育等。
- 系统:Google Co-Scientist(生成-辩论-演化循环 + Elo 排名)、Agent Laboratory(教授/博士后/评审多角色协作)。
- 策略:使用 ε-greedy、UCB、Thompson Sampling、模拟退火等方法平衡探索与利用。
- 挑战:高成本、评估难、幻觉与安全风险;需要优先级排序、验证机制、安全审查。
是什么:探索与发现的核心定义
探索与发现模式:智能体主动寻找新信息、发现新可能性、识别未知之未知,而非仅在预定义空间内优化或做出反应。
与传统模式的区别:
传统优化 → 在已知空间内寻找最优解
探索发现 → 主动进入未知领域,生成新知识为什么:典型场景与价值
- 科学研究自动化:药物发现 → 生成假设、设计实验、执行验证、分析优化。
- 游戏与策略生成:探索状态空间、发现涌现策略、识别环境漏洞。
- 市场研究:扫描社交/新闻、识别趋势、预测机会。
- 安全漏洞发现:渗透测试、探测弱点、发现未知漏洞。
- 创意内容生成:探索风格组合、生成原创作品。
- 个性化教育:发现学生盲区、探索最优学习路径。
价值总结:发现真正创新、识别风险与机会、扩展知识边界、提升自主性。
怎么做:多智能体协作与探索策略
Google Co-Scientist(协作科学家)
| 智能体 | 角色 | 功能 |
|---|---|---|
| Generation Agent | 生成器 | 文献探索、模拟辩论,生成假设 |
| Reflection Agent | 反思者 | 同行评审,评估正确性、新颖性 |
| Ranking Agent | 排名者 | 基于 Elo 评级排序假设 |
| Evolution Agent | 演化者 | 优化高 Elo 假设 |
| Proximity Agent | 邻近分析 | 聚类相似想法 |
| Meta-review Agent | 元评审 | 综合评审,识别模式 |
核心机制:测试时计算扩展、生成-辩论-演化循环、Elo 排名。
验证成果:在药物再利用、靶点发现、抗菌素耐药性任务中取得突破,并通过实验验证。
局限与安全:付费墙文献、负面结果缺失、LLM 幻觉、计算成本高;通过安全审查、对抗测试、可信测试者计划缓解。
Agent Laboratory 框架
四个阶段:文献综述 → 实验设计与执行 → 报告撰写 → AgentRxiv 知识共享。
多智能体角色:Professor(战略)、PostDoc(执行)、ML/SW Engineer(实现)、Reviewer(评估)。
特色:三方评审、Elo 打分、自动化报告、知识共享平台。
探索-利用平衡策略
| 策略 | 原理 | 场景 |
|---|---|---|
| ε-greedy | ε 概率探索,1-ε 利用 | 简单决策 |
| UCB | 优先选择不确定性高的选项 | 多臂老虎机 |
| Thompson Sampling | 贝叶斯采样 | 在线广告 |
| 模拟退火 | 初期多探索,后期多利用 | 优化问题 |
import random
def epsilon_greedy(epsilon, known_best, alternatives):
if random.random() < epsilon:
return random.choice(alternatives)
return known_best实战指南
1. 构建探索智能体
class ExplorationAgent:
def __init__(self):
self.knowledge_base = {}
self.exploration_history = []
self.curiosity_score = 0.5
def explore(self, environment):
unexplored = self.identify_unexplored(environment)
values = self.evaluate_exploration_value(unexplored)
target = self.select_target(values)
result = self.execute_exploration(target)
self.update_knowledge(result)
return result2. 多智能体辩论与迭代
class DebateSystem:
def __init__(self, agents):
self.agents = agents
self.elo_ratings = {agent: 1500 for agent in agents}
def debate(self, hypothesis_a, hypothesis_b):
arguments_a = [agent.argue_for(hypothesis_a) for agent in self.agents]
arguments_b = [agent.argue_for(hypothesis_b) for agent in self.agents]
winner = self.judge(arguments_a, arguments_b)
self.update_elo(hypothesis_a, hypothesis_b, winner)
return winnerdef generate_debate_evolve_loop(problem, max_iterations=10):
hypotheses = generate_initial_hypotheses(problem)
for _ in range(max_iterations):
ranked = debate_tournament(hypotheses)
top_k = ranked[:5]
evolved = evolve_hypotheses(top_k)
new_hypotheses = generate_variants(evolved)
hypotheses = evolved + new_hypotheses
if converged(hypotheses):
break
return ranked[0]优势与挑战
| 优势 | 说明 |
|---|---|
| 真正创新 | 发现未知之未知 |
| 自主性 | 主动设定探索目标 |
| 知识扩展 | 突破预训练限制 |
| 加速发现 | 自动化高成本探索 |
| 增强人类 | 人机协作共同探索 |
| 挑战 | 影响 | 缓解 |
|---|---|---|
| 计算成本高 | 大量迭代消耗资源 | 优先级排序、提前停止 |
| 评估困难 | 难量化创新价值 | 多维度评估、专家/LLM反馈 |
| 幻觉风险 | 生成虚假发现 | 多重验证、实验验证 |
| 安全风险 | 可能发现危险知识 | 安全审查、伦理约束 |
| 知识整合难 | 碎片化发现难整合 | 元评审、知识图谱 |
FAQ
Q1:探索与发现 vs RAG?
RAG 检索已知知识,探索与发现生成新知识;RAG 可作为探索工具。
Q2:如何衡量探索成功?
新颖性评分、实验验证率、专家评价、实际应用价值、与已知知识的距离。
Q3:如何防止偏离目标?
明确探索边界、阶段性评估、监督 Agent 引导、定期回归主题。
Q4:如何防止危险知识?
输入审查、输出过滤、人类监督、伦理约束、可信测试者计划。
Q5:个人/小团队能做吗?
可实现简化版:用开源框架、减少智能体、降低迭代、聚焦细分领域。
Q6:ROI 如何?
短期成本高、收益不确定;长期突破带来巨大价值,适合创新驱动场景。
延伸阅读与引用
总结
探索与发现模式让智能体主动寻找未知可能、推动创新。借助多智能体协作(生成-辩论-演化)、Elo 排名、探索-利用平衡策略,智能体可以在未知领域生成高质量假设、发现新机会。虽然探索成本高、评估难、存在安全风险,但通过优先级排序、验证机制和安全审查,可以在创新与风险之间取得平衡。