STM 作用:记住会话历史、支持线程恢复
- 创建方式:<code>create_agent(..., checkpointer=InMemorySaver/PostgresSaver)</code>
- AgentState:默认含 <code>messages</code>,可扩展字段(user_id、preferences 等)
- 常见策略:Trim / Delete / Summarize / Custom
- 工具写入:Tool 返回 <code>Command(update=...)</code> 修改 state
- Middleware:<code>@before_model</code>、<code>@after_model</code>、<code>@dynamic_prompt</code>
- 线程管理:<code>configurable.thread_id</code> 区分会话
- 生产注意:数据库持久化、加密、配额
概述
对于人工智能体而言,记忆至关重要,因为它能让它们记住之前的交互、从反馈中学习并适应用户的偏好。随着智能体处理更复杂的任务,涉及大量用户交互,这种能力对于提高效率和提升用户满意度都变得必不可少。
对话历史是最常见的短期记忆形式。Short-term memory(STM)常用于在单个线程内保存对话历史,让 Agent 记住最近的交互、反馈与工具结果,从而保持上下文连贯。太长的内容可能让大模型痛失焦点,同时还会面临响应速度变慢和成本增加的问题。
聊天模型通过消息接收上下文,这些消息包括指令(系统消息)和输入(人类消息)。可以详见第三章节中关于信息Messages的描述。
STM核心机制是通过 <code>checkpointer</code> 持久化 <code>AgentState</code>,每次模型调用前读取,调用/工具完成后写回。
实现方式
LangChain的智能体将短期记忆作为智能体状态的一部分进行管理。通过将这些存储在图的State中,智能体可以访问特定对话的完整上下文,同时保持不同线程之间的分离。State通过检查点工具持久化到数据库(或内存)中,因此线程可以随时恢复。当智能体被调用或某个步骤(如工具调用)完成时,短期记忆会更新,并且在每个步骤开始时会读取该状态。
checkpointer:存储的工具
Langchian中的常见用法是在创建智能体时指定一个<code>checkpointer</code>,是负责 “会话状态持久化” 的组件。核心功能是:将 AI 代理的 完整会话状态(包括消息历史、自定义字段如 <code>user_id</code>/<code>preferences</code>、工具调用记录等)存储到指定介质(内存、数据库等),并在需要时(如后续会话轮次、会话中断恢复)读取该状态,确保代理 “不会忘记之前的信息”。在实际操作中常常使用数据库来作为<code>checkpointer</code>来存储信息。
<code>checkpointer</code>有三大作用:
- 跨轮次记忆:让代理 “连贯对话”,没有 checkpointer 时,代理每次 <code>invoke</code> 都是 “全新会话”—— 即使你第二次调用时传入相同 <code>user_id</code>,代理也无法识别这是同一个用户的历史会话。而 checkpointer 会通过 <code>thread_id</code>(线程 ID) 关联状态
- 会话恢复:应对中断场景,若会话过程中出现网络波动、服务重启,没有 checkpointer 会导致所有状态丢失,用户需要重新输入信息;有 checkpointer 时,只要保留 <code>thread_id</code>,重启后通过 checkpointer 读取该线程的历史状态,就能无缝恢复到中断前的对话进度
- 状态一致性:统一管理多维度信息,自定义的 <code>CustomAgentState</code> 包含 <code>messages</code>(消息)、<code>user_id</code>(身份)、<code>preferences</code>(偏好)等多维度信息,checkpointer 会将这些信息 作为一个完整的 “状态快照” 存储,避免部分信息丢失(如只存消息、丢了用户偏好),确保代理每次读取的状态都是完整、一致的。
AgentState:要存的内容
上面提到了额外的字段来补充上下文,这就需要使用<code>AgentState</code>来管理,具体而言是通过<code>messages</code>键来管理对话历史。如下方代码示例
class CustomAgentState(AgentState):
user_id: str
preferences: dict
agent = create_agent(
"gpt-5", # 模型名称(网页示例中常用gpt-5/gpt-4o系列)
[get_user_info], # 工具列表
state_schema=CustomAgentState, # 自定义状态 schema
checkpointer=InMemorySaver(), # 内存型检查点
)
result = agent.invoke(
{
"messages": [{"role": "user", "content": "Hello"}], # 会话消息
"user_id": "user_123", # 自定义状态:用户ID
"preferences": {"theme": "dark"} # 自定义状态:用户偏好
},
{"configurable": {"thread_id": "1"}} # 线程ID
)上述代码中,默认<code>AgentState</code>仅能记住消息,无法关联用户身份、偏好等关键信息;所以通过自定义<code>CustomAgentState</code>+ 绑定检查点 + 指定线程 ID,实现了 “消息 + 用户属性” 的联合记忆,为后续功能(如工具根据用户 ID 查询信息、提示词根据偏好个性化)打下基础。当然这一点也存在另外一个风险,将userid等信息代入上下文,也将导致上下文的缓存命中率降低,在Manus团队i分享的文章中也提到了这一点。
两者的区别和关联
把 <code>AgentState</code> 看作你手机里的 “聊天记录 + 个人设置”(比如微信的聊天内容、字体大小、深色模式偏好),把 <code>checkpointer</code> 看作手机的 “自动保存功能”—— 前者是 “要存的内容”,后者是 “存内容的工具”,两者必须配合才能让信息不丢失。
- AgentState(内容):是 AI 代理的 “记忆内容本身”,包含所有需要记住的信息(比如用户说过的话、用户 ID、偏好设置等),就像你手机里 “微信的全部数据”。
- checkpointer(工具):是 “保存 / 读取这些记忆内容的工具”,负责把 AgentState 存到安全的地方(内存、数据库),并在需要时取出来,就像手机 “把微信数据存到本地硬盘” 的功能。
模式 & 短期记忆的处理方式
大多数大语言模型都有一个最大支持的上下文窗口(以令牌为单位)。较长的对话可能会超出大语言模型的上下文窗口,常见有以下三种方式。
Trim message修剪消息
修剪的规则可能有很多,可以是按照条数也可以按照token数量来判断。
Langchian可以根据令牌数量,并在接近该限制时进行截断。先知道你用的模型 “最大能装多少令牌”,每次对话新增消息后,都计算 “当前所有消息历史的总令牌数”,当总令牌数 “接近上限”,就触发 “截断操作”。
该部分有两个参数,一个是<code>max_tokens</code>,明确截断后,最终要留下多少令牌的消息;另一个是<code>strategy</code>,明确 “该删哪些、留哪些”,最常用的就是 “保留最近的消息”—— 因为对话中 “刚说的内容通常更重要”(比如用户刚问的 “我的订单号是多少”,比 10 轮前聊的 “今天天气如何” 更关键)。常见的<code>strategy</code>还包括保留 “开头 + 结尾”(比如保留最早的 1 条消息+ 最近的 N 条消息)。
Delete messages 删除消息
在Langchian中也可以从图状态中删除消息以管理消息历史。要从图状态中删除消息,需要使用<code>RemoveMessage</code>,并将状态键与<code>add_messages</code>一起使用。删除消息时,务必确保生成的消息历史是有效的,如一些提供商要求消息历史以一条<code>user</code>消息开始,大多数提供商要求带有工具调用的<code>assistant</code>消息后必须跟有相应的<code>tool</code>结果消息;即删除消息一定是“成套”的删除。
删除消息与修剪一样,也会涉及一个问题:该删除什么消息。官方文档中未明确说明,但依然可在自己业务逻辑中进行约定,比如删除较早的消息、删除某个消息角色的消息、删除某些内容特征的消息等。优先删 “AI 回复、重复内容、无关闲聊”,绝对保留 “用户身份、关键需求、业务核心信息”。
以下是代码示例:
from langchain.messages import RemoveMessage
def delete_messages(state):
messages = state["messages"]
if len(messages) > 2:
# remove the earliest two messages
return {"messages": [RemoveMessage(id=m.id) for m in messages[:2]]}Summarize messages 总结消息
修剪或删除消息的问题在于,可能会因剔除消息队列而丢失信息,所以总结消息可能是一种比较好的办法。要在智能体中总结消息历史,请使用内置的<code>SummarizationMiddleware</code>。通过 <code>SummarizationMiddleware</code>(总结中间件),在对话消息接近模型令牌上限时自动生成 “对话摘要”,既避免模型上下文超容,又能让代理记住关键信息
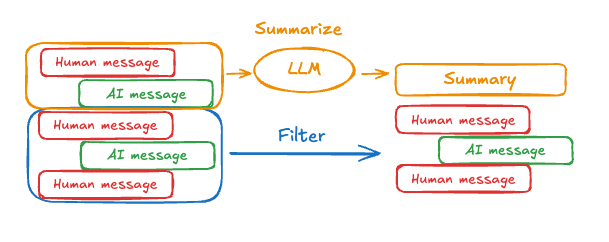
示例代码如下:
agent = create_agent(
model="gpt-4o", # 主模型:负责生成最终回复(如回答“你叫Bob”)
tools=[], # 工具列表:此处为空(代理无需调用外部工具)
middleware=[ # 中间件:核心是 SummarizationMiddleware(记忆优化)
SummarizationMiddleware(
model="gpt-4o-mini", # 摘要模型:轻量模型,专门用来生成对话摘要(更高效)
trigger={"tokens": 4000}, # 触发条件:当对话总令牌数接近4000时,自动生成摘要
keep={"messages": 20}, # 保留规则:即使生成摘要,也保留最近20条原始消息
)
],
checkpointer=checkpointer, # 绑定检查点:将“消息+摘要”存储到内存
)<code>SummarizationMiddleware</code> 有 3 个关键参数:
- <code>model</code>:生成摘要用的 “轻量模型”。因为生成摘要不需要复杂逻辑,可以用更高效(速度快、成本低)的LLM
- <code>trigger={"tokens": N}</code>:摘要的 “触发条件”,当对话的 原始消息总令牌数接近N时触发。除了Token限制外,有可以是其他的触发条件,如 对话轮数触发、时间间隔触发、对话主题变化触发等。其中,对话主题变化触发通过计算历史上下文片段与当前查询的相关性来判断主题是否变化,如基于 Embedding 的相似度过滤,计算上下文片段与查询的余弦相似度,当低于某个阈值时,可认为主题发生了较大变化,进而触发 SummarizationMiddleware,只保留与新主题相关度高的片段。
- <code>keep={"messages": N}</code>:摘要生成后的 “保留规则”,会保留 最近 20 条原始消息(而不是全删)。因为 “刚聊的内容通常更关键”(比如用户刚问 “我的名字是什么”,最近的消息里有 “我叫 Bob”,不需要依赖摘要),保留原始消息能让回复更精准。
访问和修改STM
AI 代理的 “短期记忆” 本质是<code>AgentState</code>(状态数据),里面存着对话中需要记住的所有信息 —— 比如用户说过的话(<code>messages</code>)、用户 ID(<code>user_id</code>)、偏好设置(<code>preferences</code>)等。
- Tools 工具:Read 读取短期记忆:使用<code>ToolRuntime</code>参数在工具中访问短期记忆(状态),通过<code>ToolRuntime</code>参数(相当于 “备忘录钥匙”),偷偷读取代理的<code>AgentState</code>(备忘录内容),且模型看不到这个参数(避免干扰)。Write 写入短期记忆:要在执行过程中修改智能体的短期记忆(状态),可以直接从工具返回状态更新;工具执行完后,返回<code>Command(update={...})</code>(相当于 “给备忘录写备注”),直接修改代理的<code>AgentState</code>。
- Prompt :通过访问记忆,能让提示词 “动态调整”—— 根据记忆里的信息定制指令。通过用<code>dynamic_prompt</code>中间件(相当于 “提示词裁缝”),在模型生成回复前,先从记忆里读信息(比如用户名字),再把提示词改成 “定制版”。
Langchain还提供了另外两种方式:
- Before Model(调用前):比如 “修剪消息”—— 模型生成回复前,先从记忆里读所有消息,删掉没用的,避免超出 token 限制(比如只留最近 3 条消息)。类比:助理回复前,先整理备忘录,删掉 1 个月前的无关聊天,只看最近的对话,避免答非所问。
- After Model(调用后):比如 “删除敏感信息”—— 模型生成回复后,检查记忆里的消息,删掉包含 “密码”“手机号” 的内容,避免泄露。类比:助理回复后,再翻一遍备忘录,删掉你不小心说的 “银行卡号”,确保安全。
知识点拆解
| 模块 | 关键点 | 产品关注 |
|---|---|---|
| Checkpointer | <code>InMemorySaver</code> 适合开发,生产推荐 Postgres/自建存储;支持自动建表 | 需决定持久化介质、容量、备份策略 |
| AgentState | 默认包含 <code>messages</code>(使用 <code>add_messages</code> reducer);可继承添加字段 | PRD 中定义需要持久字段(如 user_id、preferences)及默认值 |
| Thread 管理 | <code>{"configurable":{"thread_id":"123"}}</code> 指定会话,支持并行多线程 | 前端需传 thread_id,后端需鉴权以防串线 |
| Trim | 通过 <code>@before_model</code> 裁剪消息(按条数或 tokens) | 需设定阈值、策略(保留首条 system + 最近 N 条) |
| Delete | 使用 <code>RemoveMessage</code> 或 <code>REMOVE_ALL_MESSAGES</code> 永久删除 | 定义“清空上下文”操作的触发条件(用户命令/敏感数据) |
| Summarize | 将早期消息总结后替换,维持上下文而减 token | 指定何时总结、总结格式、是否展示给用户 |
| 自定义策略 | 可组合过滤、标签化等个性裁剪 | 需求中描述可插拔策略,便于后期扩展 |
| 扩展 state/schema | <code>state_schema=CustomAgentState</code>、<code>context_schema=CustomContext</code> | 说明新增字段的来源、权限、存储位置 |
| 工具写入 state | Tool 通过 <code>Command(update={...})</code> 或写入 <code>messages</code>/自定义字段 | 明确哪些工具可修改记忆,如何审计 |
| Middleware | <code>@dynamic_prompt</code> 基于 state 生成 system prompt;<code>@after_model</code> 做敏感词过滤 | 需求中列出所需中间件及触发规则 |
适用场景(问题 → 方案 → 价值)
- 会员客服的多线程回访
- 问题:客服 Bot 需在多次会话中记住会员等级与喜好。
- 方案:扩展 <code>AgentState</code> 增加 <code>membership_level</code>、<code>preferences</code>,使用 PostgresSaver 以 <code>thread_id=user_id</code> 持久化,工具查数据库后写入 state。
- 价值:跨会话保持一致体验,客服记录可随时恢复,满足合规审计。
- 长对话内容生成
- 问题:用户持续追加修改需求,容易超出上下文窗口。
- 方案:<code>@before_model</code> 统计消息条数,保留首条 system + 最近 3 轮,早期内容由总结工具生成 <code>summary</code> 并写入 state 供后续提示引用。
- 价值:在不牺牲上下文的情况下控制 token 成本,提高响应速度。
常见问题(FAQ)
- STM 与长期记忆区别?→ STM 仅在当前线程有效,长期记忆需接 store/数据库自行实现。
- 必须用 checkpointer 吗?→ 若要线程恢复或多轮对话,必须;否则状态只存在进程内存,会丢失。
- 如何选择存储?→ 开发期用 <code>InMemorySaver</code>,生产根据合规选择 Postgres、Redis 或自建方案,并做好加密/备份。
- 自定义 state 会影响性能吗?→ 字段越多序列化越重,需评估数据量并仅保存必要信息。
- 怎样避免越权访问其他线程?→ 在传入 thread_id 前进行用户鉴权,必要时对 state 加密。
- Trim 与 Delete 差别?→ Trim 只在调用前裁剪(历史仍在存储);Delete 永久移除 state 里的消息。
- Summarize 由谁执行?→ 可由专门工具或模型完成,结果写回 state 中新字段(如 <code>summary</code>)。
- 工具写入 state 有何风险?→ 需限制可写字段,避免恶意覆盖关键信息,同时在日志中记录 ToolCall ID 和变更内容。
- Middleware 顺序重要吗?→ <code>@before_model</code> 在模型调用前运行,可叠加多个;需要规划执行顺序避免相互覆盖。
- 如何在提示词中引用 state?→ 使用 <code>@dynamic_prompt</code> 或在模板中读取 state/context 字段,确保系统提示随用户信息动态更新。
扩展信息
- Short-term memory 官方指南:https://docs.langchain.com/oss/python/langchain/short-term-memory
- LangGraph Checkpointer(Postgres 等):https://github.com/langchain-ai/langgraph/tree/main/libs/checkpoint
- LangChain Agents Middleware 参考:https://reference.langchain.com/python/langchain/agents