Agents
来源:LangChain 文档导航 > Core components > Agents
链接:https://docs.langchain.com/oss/python/langchain/agents
核心概念
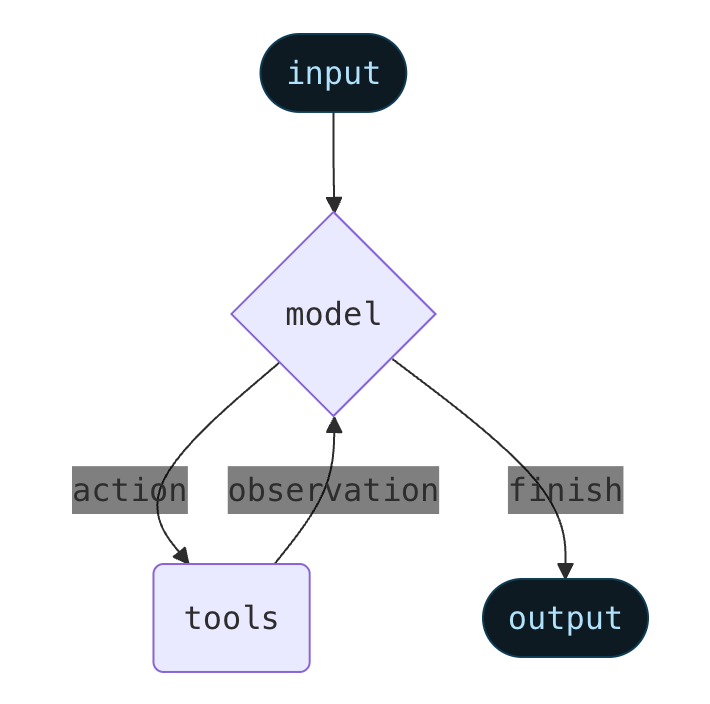
<img src="https://ymmcheer-1257617206.cos.ap-nanjing.myqcloud.com/typora/image-20251119155941453.png" alt="image-20251119155941453" style="zoom:50%;" />
{kind=link}
LangChain Agent 将语言模型、工具与中间件封装在 LangGraph 执行图中,模型与工具交替运行直至输出终止条件。大语言模型智能体会循环运行工具以达成目标。智能体会一直运行,直到满足停止条件——也就是说,当模型输出最终结果或达到迭代上限时才会停止。
核心组件
LLM大模型
模型是智能体的推理引擎,可以在需求或代码中直接指定,也可以动态的选择指定模型。
最常见的是静态模型,在创建智能体时配置一次,并且在整个执行过程中保持不变。这里从需求角度看,需要重点关注的是模型的参数,不同模型支持的参数也不同。比如常见的openai有:
- stream_usage:控制是否流式返回 API 调用的使用情况(如 token 消耗)
- temperature:控制生成内容的随机性,值越高随机性越强(0-2 之间)
- max_tokens:限制生成内容的最大 token 数(输入 + 输出总 token 不超过模型上限)
- timeout:设置 API 调用的超时时间(秒),超时未响应则终止请求
- reasoning_effort:控制模型推理的努力程度(LangChain 扩展参数,非 OpenAI 原生)
- max_retries:设置 API 调用失败时的最大重试次数
- api_key:OpenAI API 的密钥,用于身份验证
- base_url:自定义 API 请求的基础 URL(如使用代理或私有部署的模型)
- organization:OpenAI 组织 ID,用于关联 API 调用的组织(多组织账号时使用)
根据上下文、路由或成本因素,也可以选择动态模型方式,在不同情况下选择不同的大模型。比如上下文较长时候选择更高级或上下文更长的模型等。
工具
工具是智能体的 “行动载体”—— 工具本身具备执行特定任务的能力(如查天气、调用 API、查数据库),而智能体通过调用工具,才能从 “仅生成文本” 升级为 “实际采取行动”(比如用户问 “今天北京天气适合出游吗”,智能体需调用 “天气查询工具” 获取数据,再判断是否适合出游)。
Agent相较于 Function call有明显区别:Function call 是 “执行具体任务的技术手段”,而 Agent 是 “统筹任务、决策调用逻辑的智能主体”。一个相当于是大脑,一个是执行。Agent的价值在于 统筹与决策能力:多工具连续调用、并行工具调用、动态选工具、容错与重试、状态持久化:即上下文工程。
工具的使用需要进行约定,没有约定LLM也无法完成工具的使用;如果提供的工具列表为空,智能体将由单个大型语言模型节点组成,且不具备工具调用能力。
工具的调用还存在另外一个需要关注的点:工具调用失败。失败可能源于多种场景(如参数错误、网络超时、工具服务异常等)。工具调用失败的处理需遵循 “拦截 - 分类 - 反馈 - 决策” 四步流程。在需求中,可以针对性为开发同学进行约定,同时万一有一些无法规避的错误暴露给用户后,支持用户自行的重试或引导。
- 拦截:通过 <code>@wrap_tool_call</code> 等中间件拦截工具执行的所有异常;
- 分类:按错误类型(参数错误、网络故障、服务不可用)分类处理;
- 反馈:生成标准化 <code>ToolMessage</code>(含 <code>tool_call_id</code>),告知 Agent 错误详情与处理建议;
- 决策:Agent 基于错误信息自动决策(重试、切换工具、提示用户修正输入),融入 ReAct 循环实现闭环。
提示词Prompt
提示词的核心作用是 定义身份、规范响应风格、限定任务边界。
最基础的提示词用法是通过 <code>system_prompt</code> 参数为 Agent 设定 “底层行为框架”,若未显式传入 <code>system_prompt</code>,Agent 会自动从输入的<code>messages</code>(用户请求、对话历史)中推断任务目标。
更高级的用法是动态提示词(Dynamic Prompt) 方案 —— 通过中间件(Middleware)根据 “运行时上下文”(如用户角色、对话长度、任务复杂度)实时生成或修改提示词。举几个特定的例子:
- 基于 user_role 生成提示词,比如不同专业能力分层的用户可使用不同的提示词
- 基于权限划分提示词,比如权限高的用户可授权访问一些敏感的数据或工具
- 基于Token消耗或对话轮次,引导大模型进行内容的总结
- 基于变量注入,比如根据用户信息查询订单数据等
动态提示词一定程度上算得上下文工程的范畴,后续针对性的学习和梳理。
Structured output结构化输出
结构化输出模块的核心目标是让 Agent 的响应从 “非结构化自然语言” 转变为 “符合预设格式的规范数据”。官方文档中也有专门的篇幅介绍该部分,这里做简单的扩展。一是格式约定,比较常用的是json结构,当然也可以是其他的Scheme类型;另外一个是实现策略或路径,官方文档提供了<code>ToolStrategy</code>与<code>ProviderStrategy</code>两个策略,尚未进一步确认但应该也还有其他的策略或约定。
Memory 记忆
Memory(记忆) 是 Agent 实现 “上下文连贯、历史信息复用” 的核心组件,本质是通过 “state” 让 Agent 记住对话过程中的关键信息(如对话历史、用户偏好、工具调用结果),避免重复提问或信息丢失。Memory 并非独立组件,而是通过 Agent 的 State(状态) 实现,核心作用是为 Agent 提供 “短期记忆”,支撑其在多轮交互中保持逻辑连贯。
State是LangGraph中的概念,可以理解为一组元数据,是一个共享的数据容器,保存着整个 AI 应用的 "当前快照",就像一个随身携带的笔记本,记录着所有重要信息。
Memory 是 “短期记忆”,仅在当前 Agent 会话中有效(会话结束后状态重置);若需 “长期记忆”(如跨会话保存用户偏好),需额外对接外部存储(如 Redis、数据库),官方文档未内置长期记忆功能,需自行扩展。
扩展阅读
- LangChain Tools 指南:了解工具装饰器、并行策略与参数校验。
- LangGraph Graph API:掌握节点、边及状态管理,便于自定义执行流。