导语
传统LLM像闭卷考试,只能靠记忆回答,信息过时且可能产生幻觉。RAG(检索增强生成)像开卷考试,在生成响应前从外部知识库检索相关信息并增强提示词,使AI能够基于实时、可验证数据生成准确答案。本文介绍RAG核心概念、三种演进形式(标准RAG、图RAG、智能体式RAG)、向量数据库选型与实战案例,适合需要构建知识问答系统的开发者。
TL;DR
- 核心:RAG在LLM生成响应前,从外部知识库检索相关信息并增强提示词,使AI能够基于实时、可验证数据生成准确答案。
- 价值:访问最新信息、降低幻觉风险、利用专业知识、提供可验证引用、无需重新训练模型。
- 流程:用户查询 → 语义搜索知识库 → 提取最相关信息片段 → 增强原始提示词 → LLM生成基于事实的响应。
- 演进:标准RAG(简单检索+增强)→ 图RAG(知识图谱)→ 智能体式RAG(引入推理层)。
- 技术:嵌入(Embeddings)、语义相似度、分块(Chunking)、向量数据库、混合搜索(BM25+向量)。
是什么:RAG的核心定义
RAG(检索增强生成):在LLM生成响应前,从外部知识库检索相关信息并增强提示词,使AI能够基于实时、可验证数据生成准确答案。
核心类比:
传统LLM → 闭卷考试(只靠记忆)
RAG系统 → 开卷考试(可查阅资料)工作流程:
用户查询
↓
语义搜索知识库(不是关键字匹配)
↓
提取最相关信息片段
↓
增强原始提示词(查询+检索内容)
↓
LLM生成基于事实的响应可视化示意图:
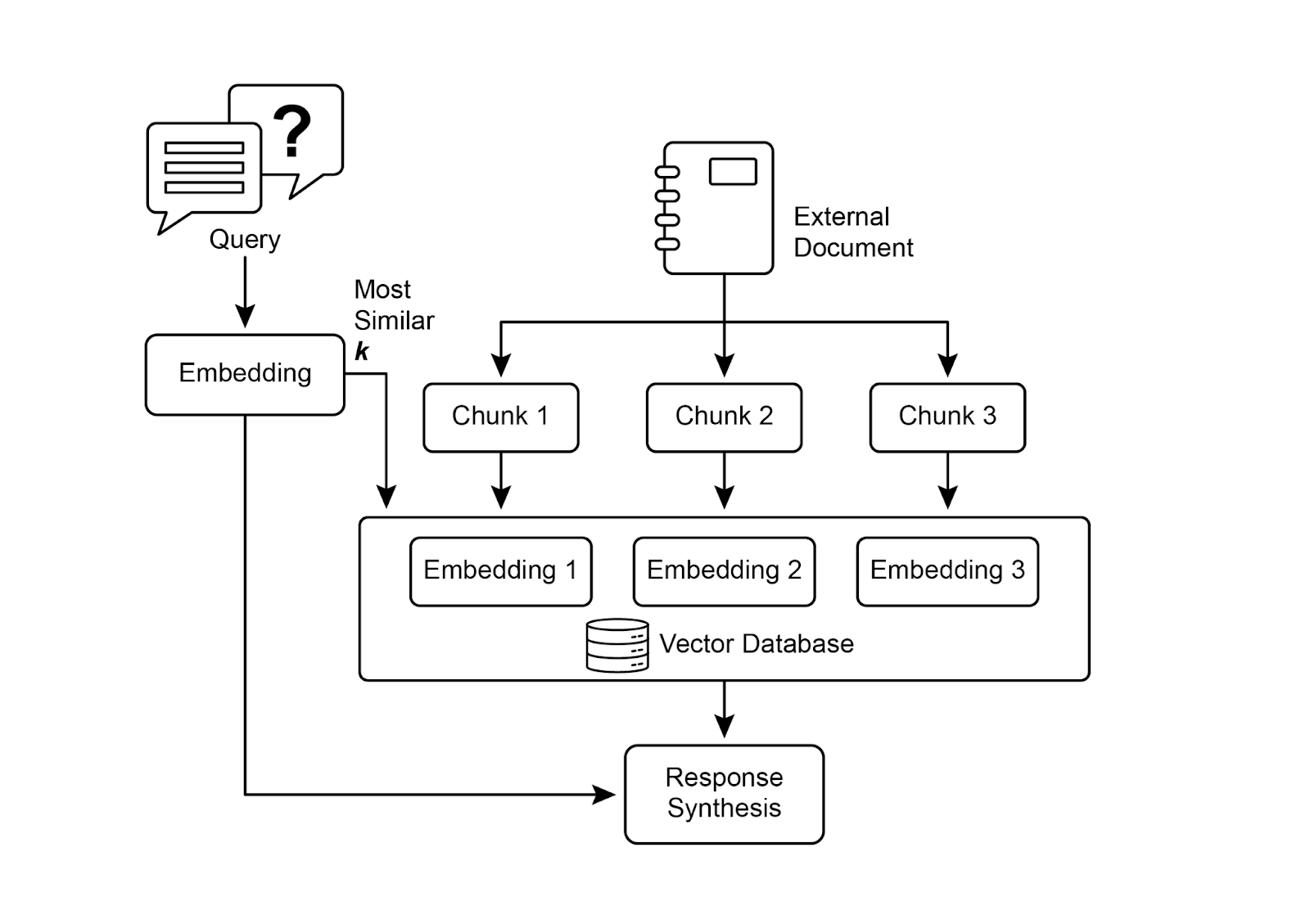
图1:RAG核心流程 - 分块→嵌入→向量存储→语义检索
读图要点:文档分块、嵌入向量化、存储到向量数据库、语义检索相关片段、增强提示词生成答案。
常见误解澄清:
- ❌ RAG就是向量搜索:RAG包含检索和生成两个环节,向量搜索只是检索方式之一。
- ❌ RAG可以完全消除幻觉:RAG降低幻觉风险,但不保证100%准确,仍需验证。
- ❌ 所有场景都需要RAG:简单问答、固定知识库场景不需要RAG,需要实时信息、专业知识时用RAG。
为什么:产生背景与适用场景
产生背景
LLM局限与RAG解决方案:
| LLM局限 | 影响 | RAG解决方案 |
|---|---|---|
| 静态训练数据 | 信息过时,无法获取最新资讯 | 连接实时知识库 |
| 幻觉(Hallucination) | 生成虚假信息 | 基于可验证数据回答 |
| 缺乏专业知识 | 无法访问公司内部文档 | 整合私有知识库 |
| 无法提供来源 | 答案不可验证 | 附带引用和出处 |
| 领域知识不足 | 专业领域表现差 | 动态加载领域文档 |
核心优势:
- ✅ 访问最新信息
- ✅ 降低幻觉风险
- ✅ 利用专业知识
- ✅ 提供可验证引用
- ✅ 无需重新训练模型
RAG核心概念
| 概念 | 定义 | 作用 |
|---|---|---|
| Embeddings(嵌入) | 文本的数字向量表示 | 捕捉语义含义,在高维空间中相近含义的词距离近 |
| 语义相似度 | 基于含义而非词语的相似程度 | "furry feline"与"cat"高度相似 |
| Chunking(分块) | 将大文档分割成小片段 | 提高检索效率和相关性 |
| 向量数据库 | 专门存储和查询嵌入的数据库 | 高效语义搜索(FAISS/Pinecone/Weaviate) |
| 语义搜索 | 理解意图的智能搜索 | 超越关键字匹配,理解查询背后的概念 |
怎么做:RAG的三种演进形式与实战实现
1. 标准RAG(Basic RAG)
特点:简单检索+增强
流程:查询 → 检索 → 拼接 → 生成
适用:基础问答、文档查询2. 图RAG(Graph RAG)
特点:使用知识图谱而非向量库
优势:
- 理解实体间显式关系
- 综合多文档碎片化信息
- 提供更细致的上下文推理
劣势:
- 构建和维护成本高
- 灵活性差
- 延迟更高
适用:复杂金融分析、科研(基因-疾病关系)3. 智能体式RAG(Agentic RAG)⭐
核心创新:引入推理和决策层
| 能力 | 示例场景 | 价值 |
|---|---|---|
| 来源验证 | 识别2025政策文档比2020博客更权威 | 确保答案最新准确 |
| 冲突协调 | 预算提案€50K vs 财报€65K | 选择最可靠来源 |
| 多步推理 | "我们产品vs竞品"→分解为4个子查询 | 综合复杂答案 |
| 识别知识差距 | 内部库无昨日新闻→调用Web搜索API | 动态使用外部工具 |
工作流程:
用户查询
↓
检索初步结果
↓
智能体评估
├─ 来源是否权威?
├─ 信息是否冲突?
├─ 是否需要分解查询?
└─ 是否需要外部工具?
↓
优化后的上下文
↓
LLM生成可靠答案⚠️ 挑战:
- 复杂性↑:设计实现维护成本高
- 延迟↑:多轮推理增加响应时间
- 新错误源:推理缺陷可能导致误判
检索技术对比
| 技术 | 原理 | 优势 | 劣势 |
|---|---|---|---|
| 关键字搜索(BM25) | 词频匹配 | 快速、精准匹配 | 无法理解语义 |
| 向量搜索 | 语义相似度 | 理解含义、发现概念关联 | 计算成本高 |
| 混合搜索 | 结合BM25+向量 | 兼顾精度和语义 | 实现复杂 |
实战示例
1. ADK + Google Search
from google.adk.tools import google_search
from google.adk.agents import Agent
search_agent = Agent(
name="research_assistant",
model="gemini-2.0-flash-exp",
instruction="帮助用户研究主题,使用Google Search工具",
tools=[google_search]
)2. ADK + Vertex AI RAG
from google.adk.memory import VertexAiRagMemoryService
RAG_CORPUS_RESOURCE_NAME = "projects/xxx/ragCorpora/xxx"
memory_service = VertexAiRagMemoryService(
rag_corpus=RAG_CORPUS_RESOURCE_NAME,
similarity_top_k=5, # 返回最相似的5个结果
vector_distance_threshold=0.7 # 语义距离阈值
)3. LangChain完整RAG流程
关键步骤:
# 1. 文档加载和分块
loader = TextLoader('./document.txt')
documents = loader.load()
text_splitter = CharacterTextSplitter(chunk_size=500, chunk_overlap=50)
chunks = text_splitter.split_documents(documents)
# 2. 嵌入并存储到向量数据库
vectorstore = Weaviate.from_documents(
documents=chunks,
embedding=OpenAIEmbeddings()
)
retriever = vectorstore.as_retriever()
# 3. 定义RAG链
template = """基于以下上下文回答问题:
Context: {context}
Question: {question}
Answer:"""
prompt = ChatPromptTemplate.from_template(template)
rag_chain = prompt | llm | StrOutputParser()
# 4. 执行查询
context = retriever.invoke(user_question)
answer = rag_chain.invoke({"context": context, "question": user_question})对比与取舍:RAG的优势与挑战
✅ 核心优势
| 优势 | 说明 |
|---|---|
| 实时性 | 克服静态训练数据限制 |
| 准确性 | 基于事实而非记忆 |
| 可验证性 | 提供来源引用 |
| 专业性 | 访问领域专业知识 |
| 无需重训练 | 动态更新知识 |
⚠️ 主要挑战
| 挑战 | 影响 | 缓解方案 |
|---|---|---|
| 信息碎片化 | 关键信息分散多文档 | Graph RAG/Agentic RAG |
| 检索质量 | 不相关块引入噪声 | 混合搜索+重排序 |
| 矛盾信息 | 多来源信息冲突 | Agentic RAG协调 |
| 预处理成本 | 需构建向量数据库 | 使用托管服务(Pinecone) |
| 数据同步 | 知识库需定期更新 | 自动化ETL流程 |
| 延迟增加 | 检索步骤增加时间 | 优化索引+缓存 |
| Token消耗 | 增强提示词更长 | 智能分块+摘要 |
向量数据库选型
| 类型 | 代表产品 | 适用场景 |
|---|---|---|
| 托管服务 | Pinecone, Weaviate | 快速上线、无需维护 |
| 开源方案 | Chroma DB, Milvus, Qdrant | 自主可控、可定制 |
| 扩展现有DB | pgvector(Postgres), Redis | 现有架构集成 |
| 核心库 | FAISS, ScaNN | 嵌入到应用中 |
选型考虑:
- 数据规模
- 查询QPS
- 运维能力
- 成本预算
常见错误与排错
典型坑位
| 问题 | 症状 | 识别方法 | 修复建议 |
|---|---|---|---|
| Chunk大小不当 | 检索不精准或丢失上下文 | 检查Chunk大小 | 500-1000 tokens,根据文档类型调整 |
| 检索质量差 | 返回不相关信息 | 检查检索结果 | 混合搜索+重排序,查询扩展 |
| 信息冲突 | 多来源信息矛盾 | 检查来源一致性 | Agentic RAG协调,选择最可靠来源 |
| 延迟过高 | 响应时间过长 | 检查检索和生成时间 | 优化索引,缓存结果,并行处理 |
调试技巧
- 优化Chunk策略:根据文档类型调整Chunk大小和重叠。
- 使用混合搜索:结合BM25和向量搜索,提高检索准确性。
- 实现重排序:使用重排序模型优化检索结果。
- 监控关键指标:召回率、精确率、MRR、用户满意度。
FAQ
Q1:RAG vs Fine-tuning如何选择?
A:
- RAG: 知识频繁更新、需要引用来源、多领域知识
- Fine-tuning: 改变模型行为、特定风格输出、固定领域
Q2:Chunk大小如何确定?
A:
- 太小:丢失上下文
- 太大:检索不精准
- 建议:500-1000 tokens,根据文档类型调整
Q3:如何提高检索准确性?
A:1) 混合搜索(BM25+向量);2) 重排序模型;3) 查询扩展;4) 元数据过滤;5) Agentic RAG。
Q4:如何处理多语言RAG?
A:使用多语言嵌入模型(如mBERT),或分别构建各语言知识库。
Q5:RAG如何保护隐私?
A:1) 数据脱敏;2) 访问控制;3) 本地部署;4) 审计日志。
Q6:如何评估RAG质量?
A:
- Retrieval: 召回率、精确率、MRR
- Generation: 准确性、相关性、流畅度
- End-to-End: 用户满意度
延伸阅读与引用
图片资源
- RAG核心概念
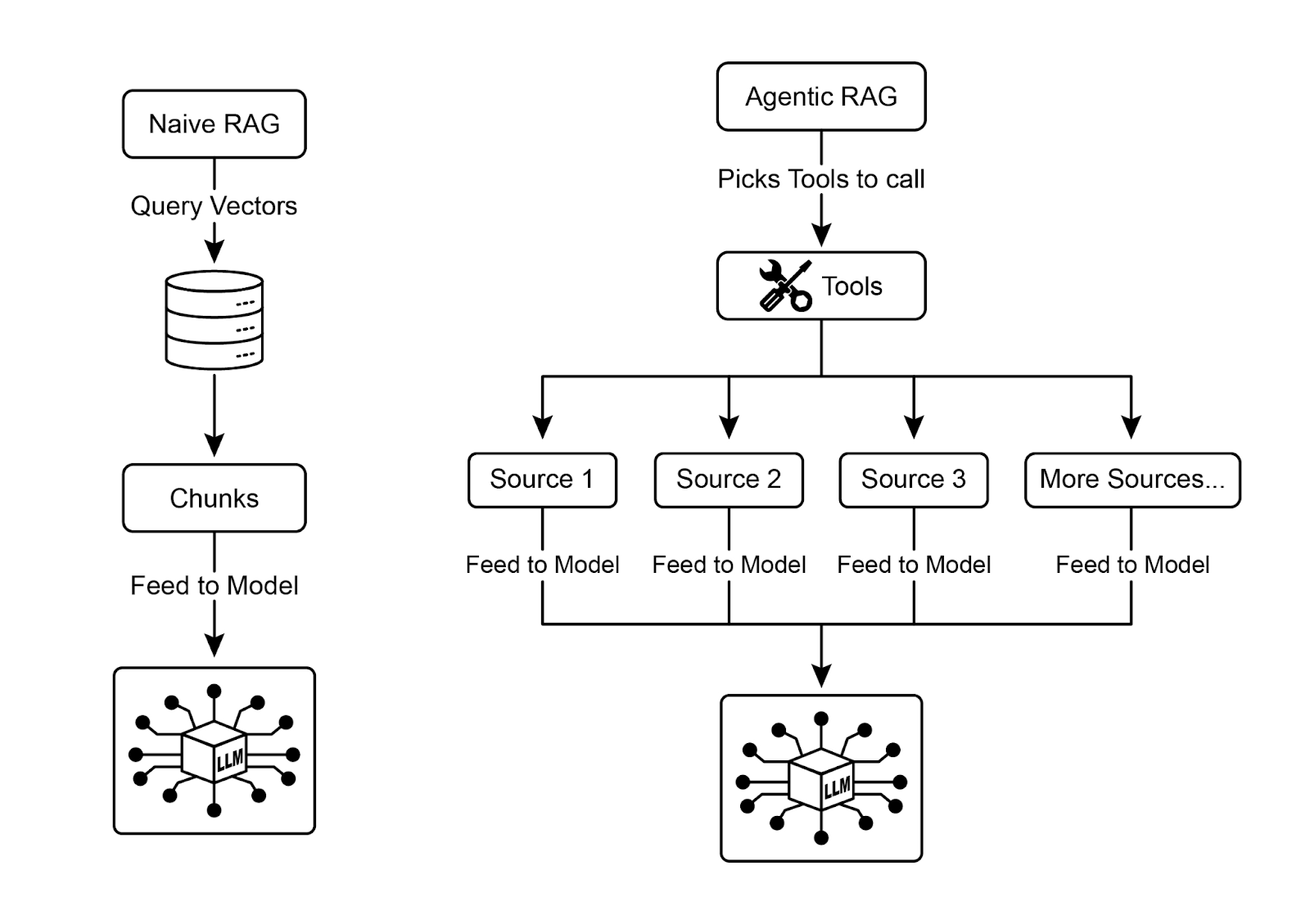 Agentic RAG
Agentic RAG 数据库检索
数据库检索 Web检索
Web检索
总结
知识检索(RAG)是突破LLM静态知识限制的核心技术。通过语义搜索外部知识库、增强提示词、生成基于事实的响应,RAG实现了访问最新信息、降低幻觉风险、利用专业知识的目标。从标准RAG到图RAG再到智能体式RAG,RAG技术不断演进,引入推理层和决策机制,显著提升了检索质量和答案可靠性。虽然RAG面临信息碎片化、检索质量、延迟等挑战,但通过混合搜索、重排序、Agentic RAG等技术可以显著缓解。